
How to do an in-depth study with Claude's Dynamic Workflows
WHAT IS THE DEPTH OF RESEARCH THAT PEOPLE IN THE AGE OF AI SHOULD DO, AND HOW TO CONSTRUCT A COMPLEMENTARY RELATIONSHIP BETWEEN ME AND AI。

In the last three years, I've been doing industry research with AI support, and I've built a series of skills and assistive systems to sort out the filtering of information, summation, connection, validation, sedimentation。
It wasn't until the week went through the dynamic workflow of Claude Code that the real meaning of the phrase "people don't fight the great times"。
THINK AGAIN: WHAT IS THE DEPTH OF RESEARCH THAT PEOPLE IN THE AGE OF AI SHOULD DO AND HOW TO CONSTRUCT A COMPLEMENTARY RELATIONSHIP BETWEEN ME AND AI。
I. Starting with the trap of research
TECHNICAL RESEARCH IS, IN FACT, A TRAP (BOTH FOR PEOPLE AND FOR AI) AND, AFTER ALL, A GREAT DEAL OF INFORMATION IS BEING RECEIVED FROM THE BEGINNING OF THE STUDY, WITH AN INCREASING NUMBER OF PERSPECTIVES AND INCREASINGLY VAGUE CONCLUSIONS. SO IT'S TIME TO UNDERSTAND THE GOAL OF RETURN ITSELF。
AND THAT'S WHY AI'S NOT GOOD ENOUGH, BECAUSE FROM THE POINT OF VIEW OF ATTENTION AND ASSOCIATIONHe will be more trapped than humans in the current amount of information and weak in truly valuable cross-border connections。
Of course, AI is good enough to be able to carry out the task of finding, summarizing, and simply avoiding the loss of detail。
although i haven't given out much publicity in the last six months, i've been looking and researching in almost all the main fields of industry, and this input is supported by my own deep-research system。
And in the face of last week's Claude Code on the line, Dynamic Workflows, I'd like to go down with each other and see if his default power is beyond me。
What is Dynamic Workflows
The core line of Dynamic Workflows is:BEFORE A MISSION IS PERFORMED, AI WILL AUTOMATICALLY DESIGN WHAT WORKFLOW SHOULD BE USED FOR THE TASK AND THEN INITIATE THE EXECUTION。
This is fundamentally different from the "plan model" and "skill" we used to use. The plan model is to tear down the task, but it does not necessarily correspond to a reasonable workflow. It is possible to add the acceptance indicator (which is essential for Research) with your hints, and you will only be better prepared to set up some harness rules if you have one。
However, dynamic workflows automatically incorporate the acceptance logic, constriction of results, and confrontation to verify these things。
the trigger is simple, directly in cc/deep-research it would then be sufficient to provide some research templates and access information, and if the ability to use dynamic workflows alone is a hint or a direct ultracode, before use, token consumes about dozens of times as much。
III. Inlined six workflow modes
the bottom of the dynamic workflow is the six core movement patterns officially summarized, which is why it is stronger than the usual dialogue/agent/skill。
In fact, there are only two core issues behind the six models: how can the task be broken? How does it fit。
3.1 & nbsp; route mode (Classify-And-Act)
the task is first identified by an agent and then distributed to the most appropriate specialized & nbsp;agent Do it. The core logic is:Logic of route selection, not parallel or iterative. One mission follows only one path, and the other path is completely non-implementation。
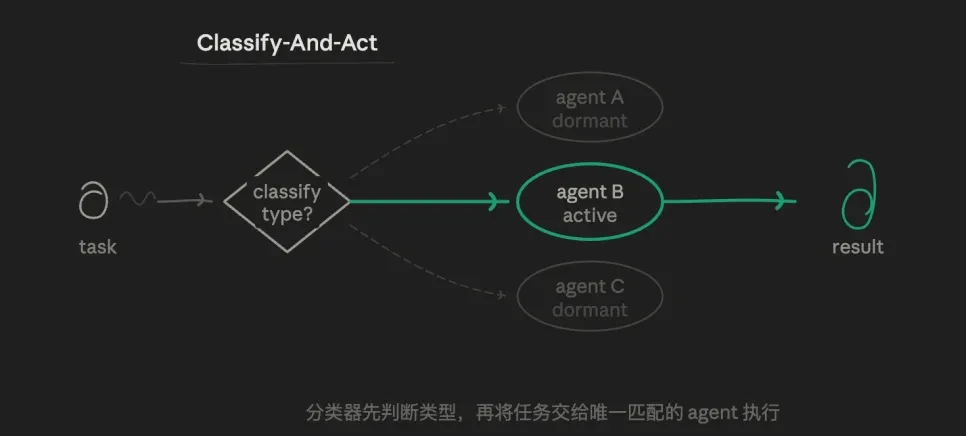
for example, i could start with three preset subagent roles: an analysis of rigorous data analysis antent, an output that is good at writing antent, a challenge that is dedicated to finding loopholes. lets routers judge who the current sub-task is for, instead of letting an individual pack。
the value of this model is that it is precise and economical, and each agent's hint can be highly independent and free from other targets, leading to vertical depth exploration. token has the lowest consumption, the fastest response. the line of responsibility is very clear。
There are also significant shortcomings and weak capacity to deal with tasks that blur borders (such as "both technical and account issues"。
3.2 Split amalgamation (Fan-out & Merge)
IT'S ALSO MY MOST COMMON MODEL, AND THE CORE LOGIC IS PARALLEL PLUS CONSOLIDATION. THE TASKS ARE SPLIT INTO N SEPARATE SUB-TASKS, RUNNING SIMULTANEOUSLY AND CONSOLIDATING THEM ONCE ALL IS COMPLETED。

the advantages are speed and isolation. the total time is about the slowest submission, not the sum of all. each submission is independent subject, without interference, and does not contaminate the other submissions because of the noise of one submission。
Weakness is that token costs are three times the number of serials, and the consolidation layer itself is difficult - how to integrate an output with an inconsistent N road structure is a design challenge. Poor division of sub-tasks leads to omissions or duplication of coverage。
3.3 & nbsp; Counter-validation (Adversral Verification)
The core logic is:Test, multiple & nbsp for the same conclusion;agent From the "refuting" point of view, it's over half the votes。
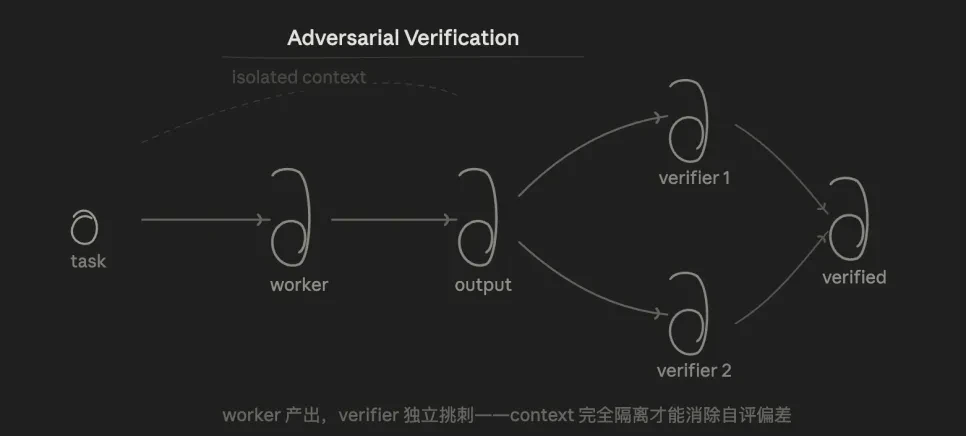
The advantage is that, because Verifier doesn't know what Walker's thinking is, it just looks at the results, and structurally eliminates the self-evaluation bias in "Let the model check the code he wrote."。
THIS PATTERN SOLVES A LONG-STANDING PROBLEM: WE OFTEN TALK TO AI IN AN ORAL WAY, BUT AI TENDS TO RESPOND TO YOUR EXPECTATIONS, AND IT'S EASY TO "RECOGNIZE BIAS." BY CONFRONTING VALIDATION, FORCING AI TO LOOK FOR A REVERSE EXAMPLE, TO TEST IT ON THE BASIS OF DATA AND EXPERIMENTS, RATHER THAN ON YOUR OWN。
But, to verify this, if he gives the wrong judgment, he'll take him to Verifier. So the preferred choice is based on repertoireable facts rather than on points of view。
I'M JUST KIDDING TO SAY THAT IF YOU LET AI FIND A PROBLEM, HE CAN DO IT ALL THE TIME, SO YOU HAVE TO LIMIT THE BOUNDARIES AT WHICH HE FINDS A PROBLEM。
3.4 Generating and Filtering (Generate & Filter)
The core logic is:It's going to spread, then it's going downi don't know. first, you deliberately create an excessive number of candidates, then you phase out it with rubric, and you keep the output high confidence。

Instead of having an agent output a "fine" answer, it's better to generate ten, then filter it with a certification layer. The advantage therefore lies in diversity. Multiple Generators can use different strategies, different hints, output solutions that are artificially difficult to anticipate, and filtering steps allow for a high concentration of final output quality。
The weakness is that the rubric mass of Filter directly determines the end effect, and the rubric design error is the end of the whole process
The appropriate scenario is a situation in which the correct answers are not known in advance, where advantages need to be drawn from a variety of possibilities, and where there is a clear need for diversity。
Fanout-And-Syntheseize is just like the surface"More roads in parallel, single output" is the easiest to confuse。
The key difference is..Intention(a) Every road in Fanout deals with different parts of the mission, the results are complementary and all paths contribute to the merger; every road in Fanout deals with the same task, the result being competition and most of the merger is discarded. The first is the puzzle, the second is the beauty pageant。
3.5 Tournament
The core logic is competitive phase-out. The N agents do the same thing on their own, by adopting & nbsp; pairwise by comparing the round-by-round phase-out, ultimately choosing the best solution.

THIS ONE I'VE DONE MANUALLY -- THE SAME CODE CHANGES TWO OR THREE VERSIONS, AND MAKES AI BETTER THAN THE RIGHT ONE. IT CAN NOW BE ORGANIZED DIRECTLY IN THE WORKFLOW。
THE ADVANTAGE IS TO JUDGE STABILITY. THE TWO CONTRASTS ( "A" AND "B" WHICH IS BETTER?") ARE MUCH MORE STABLE THAN THE ABSOLUTE RATING ( "A" RATING), BECAUSE THEY EXCLUDE THE DRIFT OF THE RATING CRITERIA. THE RESULT HAS BEEN MULTIPLE ROUNDS OF COMPETITION AND THE FINAL WINNER HAS HIGH CREDIBILITY。
It's similar to Generate-And-Filter: Both are selected from multiple candidates. The key difference is the selection mechanism: Tournament, with a comparison of two and two, is "competing candidates." When rubric is difficult to quantify and judging is by nature relative, it is more reliable。
3.6 Loop
The core logic is:From Adaptation— Continuous attempts to gather false information, supplementing the context, until the acceptance conditions are met。

IT'S ESSENTIALLY AGAINST THE RANDOMNESS OF AI: TRY MORE, ALWAYS BUMP INTO BETTER RESULTS. BUT IT WOULD BE MORE MATURE TO COMBINE CONFRONTATION CERTIFICATION AND ALLOW EACH CYCLE TO BE IMPLEMENTED WITH MORE INFORMATION, RATHER THAN SIMPLY RANDOM。
The advantage lies in the ability to handle tasks with an unknown workload. The other five models assume that the mission boundary is fixed, Loop Until Done the only one that can handle "no known how many rounds"
weaknesses are the potential risk of loss of control — stopping conditions are not well designed to circulate indefinitely. each round of anent is a completely new context that cannot accumulate a cross-wheel state (unless it is clearly written in the file)。
IV. MY OWN SKILL AND THE OFFICIAL BATLE
i designed my own set of & nbsp before dynamic work came out; deep-research my skill logic is probably this:
- Only one simple message (e.g. a new feature on a project)
- LET AI SEARCH ALL RELEVANT INFORMATION: OFFICIAL FILES, SOURCE CODES, MARKET OPINION
- Compress information into meaningful summaries
- multiple agent roles to counteranalyze and generate reports
- automatically heavy because of the high repetition rate of multiple agent content
It took me a while to find it useful。But it has a fundamental flaw: a lack of goal-oriented growth。
and many times, even if there's a fifth-step heavyweight, at this point, he often removes valuable information, and if it's not heavy enough, it's particularly easy for skill to give you a long, full text, but not to tell you, "what does this have to do with you?"。
however, for “decision-making” purposes, this is why many skills stop at the research itself, with 80 points, but less than the most critical 20 points。
TO THIS EXTENT, AFTER THE INITIAL COMPLETION OF THE STUDY, AI WILL NEED TO CONTINUE 10 REFLECTIONS AND DIALOGUE TO REACH A SATISFACTORY AND THOROUGH CONCLUSION。
What does the official dynamic work do
Through several experiments with complex research missions this week, I found that Claude Code's built-in & nbsp; Deep Research & nbsp; Workstreams (not just skill, but compile modules embedded in cc) have several key links to my own skill:
- Problem Dismantling: It does not just start searching, but starts by asking questions and breaking my questions into sub-questions: what do you really want to know? What does this have to do with you? What dimensions are worth exploring? I've done this before。
- Credibility assessment• ASSESSING PER PIECE OF INFORMATION FOR PERJURY, AN AUTHORITATIVE RATING SIMILAR TO THAT FOUND IN TRADITIONAL SEOS — IS THE SOURCE CREDIBLE? HOW MANY REFERENCES? THAT'S WHAT I DIDN'T EXPECT TO ADD。
- Cross delete instead of average merge: i used to pick all the conclusions on average, so the files are big. dynamic workflows cast votes on each conclusion, with insufficient votes being deleted and not simply merged。
- Target-oriented Output: the final report is not a stack of information, but a judgement and a proposal around your original objective. the key to this is his pre-set ability to move multiple children, and the reason why i've been skilled before is that it's easy for me to have no end-oriented orientation, because after the mass of information, i'm not sure what i'm looking forDecline of command weightsI don't know。
What have these mechanisms solved
IT'S ABOUT A COUPLE OF TYPICAL QUESTIONS ABOUT AI DOING A LONG MISSION:
Target driftThe mission starts in good shape, doesn't know what to do in the middle, and ends with a new rhythm — a lesson for humans. The longer the mission, the more obvious。
Stop early: RUNNING HARD, AI THINKS HE'S DONE, AND HE STOPS, AND IN FACT THERE'S NO ACCEPTANCE。
Context pollution: individual angents perform complex tasks, and a large number of pre-positions compress subsequent execution space. a better way to keep the pre-prompt within a few k and spread the context among multiple parties。
Output biasAI TENDS TO FOLLOW YOUR EXPECTATIONS, AND IT'S EASIER TO ASK AN ORAL QUESTION TO TRIGGER IT。
THE DYNAMIC WORKFLOW ADDRESSES THESE FOUR ISSUES IN A STRUCTURED WAY: AUTO-ACCEPTANCE INDICATORS TO PREVENT PREMATURE CESSATION; PARALLEL ISOLATION OF CONTEXT; COUNTER-VALIDATION OFFSET OUTPUT BIAS; AND DISMANTLING LAYERS OF CONSTRAINTS AI UNDERSTANDS THE TARGET BEFORE ACTION。
Summary
Finally, as a permanent researcher, the new mechanism for CCC is impressed by the fact that the six models embedded in it — route selection, splitting, anti-certification, filtering, championship campaigns, Loop circulation — cover the movement requirements of most complex research missions。
so i don't need to design angent movements manually, and i don't need to do the weighting and cross-checking myself, which are all programmed into the workflow itself。
And he is particularly well placed to think about the lack of information and the exploration of developmental issues, because the splitting of the natural doagent movement plus mission objectives has raised him again in terms of interoperability, which, three years ago, AI had done well in addressing only very clear and small issues, but the real quality of AI had to be universal, which was why his rival, from simple code to real Agent, addressed a problem from solid state to adaptation。
So, Dynamic Workflows, the dynamic workflow isn't "a smarter one-way conversation," it's just..The research process itself is structured。
I had to start a dozen independent dialogues, and now I'm down to three to four. Although the corresponding to Token consumption has increased dozens of times。
Then why three or four more times i think the root cause is these differences in demand。
Number one:The severity of the certification mechanismI'M DOING RESEARCH MAINLY ON NEW TECHNOLOGIES IN THE BLOCK CHAIN, AND MANY THINGS, OFFICIAL DOCUMENTS ARE LAGGING BEHIND, WITH MORE REFERENCE TO OPEN SOURCE CODES, CHAIN TRANSACTIONS, ETC., WHILE CURRENTLY AI DEFAULTS ARE BASED ON OFFICIAL DOCUMENTS, NOT ON FACTUAL VERIFICATION。
SecondFull cross-border deep thinkingThis, though it is possible to think about the same issue through working-flow presets (subAgent, which predefined various dimensions). But AI is good at mainstream thinking models, which are not enough for very new, very deep and lacking data。
Number three:Solutions design and validationTHE MEANING OF THE SOLUTION IS NOT TO PRESENT IT, BUT TO VALIDATE IT, TO SUPPORT IT, TO RELY ON THE MEASUREMENT OF EXISTING MECHANISMS, INPUTS AND COSTS, AND, OF COURSE, TO TEACH AI BETTER, ALTHOUGH THIS IS CONTRARY TO INTEROPERABILITY。
And finallyExtreme information enrichmentThis is about going back to the level of understanding of the audience of the message, where some people have no background and need your image, while others need your words to impress him。
