
Cách thực hiện nghiên cứu chuyên sâu với Quy trình làm việc năng động của Claude
Nghiên cứu chuyên sâu mà con người nên làm trong thời đại AI là gì và làm thế nào để xây dựng mối quan hệ hợp tác, bổ trợ giữa bản thân tôi và AI.

Trong ba năm qua, tôi không thể tách rời việc sử dụng AI để hỗ trợ nghiên cứu trong ngành. Với mục đích này, tôi cũng đã xây dựng một loạt kỹ năng và hệ thống phụ trợ để giải quyết vấn đề sàng lọc, tóm tắt, kết nối, xác minh và kết tủa thông tin.
Tuần này, cho đến khi có trải nghiệm sâu sắc về quy trình làm việc năng động của Claude Code, tôi mới khám phá ra ý nghĩa thực sự của cụm từ “Mọi người không nên chống lại thời đại lớn”.
Hãy suy nghĩ lại: Nghiên cứu chuyên sâu mà mọi người nên làm trong kỷ nguyên AI là gì và làm thế nào để xây dựng mối quan hệ hợp tác, bổ sung giữa tôi và AI.
1. Hãy bắt đầu với những cạm bẫy của nghiên cứu
Thực hiện nghiên cứu kỹ thuật thực sự đầy cạm bẫy (đối với cả con người và AI). Suy cho cùng, ngay từ khi bắt đầu nghiên cứu, bạn sẽ nhận được rất nhiều thông tin, ngày càng có nhiều thông tin và ý kiến, kết luận sẽ ngày càng trở nên mơ hồ. Vì vậy hãy luôn biết cách quay về mục tiêu của chính mình.
Đây luôn là lý do tại sao AI chưa đủ tốt, bởi vì từ góc độ của sự chú ý và liên kết,nó sẽ bị mắc kẹt trong lượng thông tin hiện tại nhiều hơn con người và nó yếu đối với các hiệp hội xuyên biên giới thực sự có giá trị.
Tất nhiên, điểm nổi bật của AI là khả năng thực thi của nó. Nó sẽ tìm kiếm, tóm tắt và tóm tắt từng lớp dưới dạng một tác nhân, điều này hoàn toàn có thể tránh được việc mất chi tiết.
Mặc dù tôi chưa xuất bản nhiều tài khoản công khai trong sáu tháng qua, nhưng tôi đã hoàn toàn chú ý và nghiên cứu về hầu hết các chiến trường chính thống trong ngành và điều hỗ trợ đầu vào và đầu ra này là một tập hợp hệ thống nghiên cứu sâu của riêng tôi.
Khi Claude Code ra mắt chức năng Quy trình công việc động vào tuần trước, tôi muốn đấu với nhau để xem liệu khả năng mặc định của anh ấy có thể hoàn toàn vượt qua khả năng của tôi hay không.
2. Quy trình làm việc động là gì
Ý tưởng cốt lõi của Quy trình làm việc động (quy trình làm việc động) là: Trước khi thực hiện một nhiệm vụ, AI sẽ tự động thiết kế quy trình làm việc nào sẽ được sử dụng để hoàn thành nhiệm vụ và sau đó bắt đầu thực thi.
Điều này về cơ bản khác với "chế độ lập kế hoạch" và "kỹ năng" mà chúng tôi đã sử dụng trước đây. Chế độ lập kế hoạch là chia nhỏ các nhiệm vụ thành nhiều chi tiết hơn, nhưng nó không nhất thiết phải tuân theo một quy trình làm việc hợp lý. Khi bạn sắp xếp các từ nhắc nhở, bạn có thể thêm các chỉ số chấp nhận (điều này rất quan trọng đối với Nghiên cứu). Tương tự như vậy, chỉ khi bạn có lời nhắc, nó mới đặt trước một số quy tắc khai thác tốt hơn.
Nhưng quy trình làm việc năng động sẽ tự động bao gồm logic chấp nhận, hội tụ kết quả và xác minh đối nghịch.
Phương pháp kích hoạt rất đơn giản. Chỉ cần sử dụng /deep-research trực tiếp trong cc rồi cung cấp một số mẫu nghiên cứu và thông tin nhập. Nếu bạn chỉ muốn sử dụng khả năng xử lý công việc động, hãy sử dụng các từ nhắc nhở hoặc nói trực tiếp ultracode. Vui lòng lưu ý trước khi sử dụng rằng mức tiêu thụ token cao hơn bình thường khoảng hàng chục lần.
3. Sáu chế độ quy trình làm việc tích hợp
Lớp dưới cùng của quy trình làm việc động là sáu chế độ lập lịch cốt lõi được tóm tắt chính thức. Đây là lý do tại sao nó mạnh hơn đối thoại/tác nhân/kỹ năng thông thường.
Trên thực tế, chỉ có hai câu hỏi cốt lõi đằng sau sáu chế độ này: Làm thế nào để phân chia nhiệm vụ? Kết quả khớp với nhau như thế nào? Tách biệt sáu tinh túy là sự hoán vị và kết hợp của cả hai.
3.1 Chế độ định tuyến (Phân loại và hành động)
Đầu tiên, tác nhân xác định loại nhiệm vụ và sau đó phân phối nhiệm vụ cho tác nhân chuyên biệt phù hợp nhất để thực hiện. Logic cốt lõi là logic lựa chọn định tuyến, không phải song song hay lặp lại. Một tác vụ chỉ có một đường dẫn và các đường dẫn khác hoàn toàn không được thực thi.
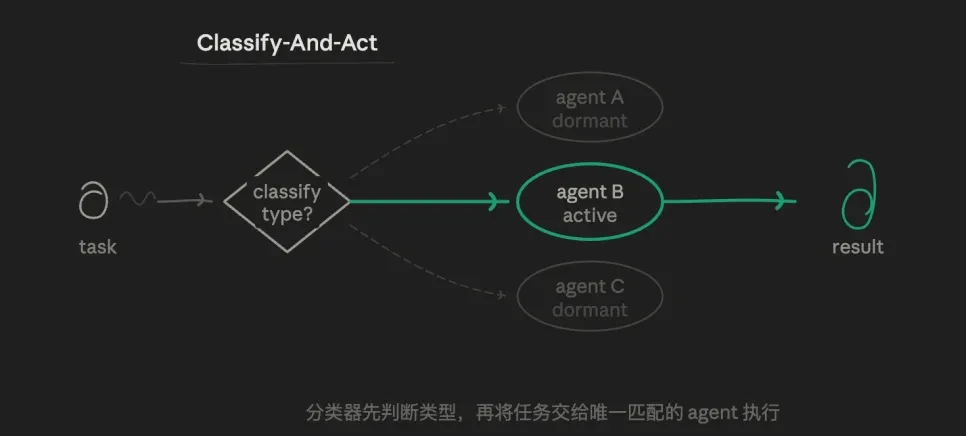
Ví dụ: tôi có thể có ba vai trò tác nhân phụ đặt trước: một tác nhân phân tích xác minh nghiêm ngặt dữ liệu và một đầu ra có khả năng viết tốt. tác nhân, một tác nhân thách thức chuyên tìm kiếm các lỗ hổng. Hãy để lớp định tuyến xác định nhiệm vụ phụ hiện tại phù hợp để chuyển giao cho ai, thay vì để một tác nhân thực hiện tất cả.
Giá trị của mô hình này nằm ở tính chính xác và tiết kiệm. Lời nhắc của mỗi tác nhân có thể mang tính độc lập cao và không bị các mục tiêu khác can thiệp, tạo thành một cuộc khám phá sâu theo chiều dọc. Mức tiêu thụ mã thông báo là thấp nhất và tốc độ phản hồi nhanh nhất. Ranh giới trách nhiệm rất rõ ràng.
Những thiếu sót cũng rất rõ ràng và khả năng xử lý các nhiệm vụ có ranh giới mờ (chẳng hạn như "cả vấn đề kỹ thuật và vấn đề tài khoản") đều yếu.
3.2 Tách và Hợp nhất (Tách ra & Hợp nhất)
Đây cũng là chế độ tôi thường sử dụng nhất. Logic cốt lõi là song song + hợp nhất. Nhiệm vụ được chia thành N nhiệm vụ con độc lập và chạy đồng thời, sau đó hợp nhất sau khi hoàn thành tất cả.

Ưu điểm là tốc độ và sự cô lập. Tổng thời gian thực hiện xấp xỉ bằng nhiệm vụ con chậm nhất chứ không phải tổng của tất cả các nhiệm vụ con. Mỗi nhiệm vụ phụ có một bối cảnh độc lập và không can thiệp lẫn nhau, tiếng ồn của một nhiệm vụ phụ cũng sẽ không làm ảnh hưởng đến các nhiệm vụ phụ khác.
Điểm yếu là chi phí mã thông báo gấp N lần so với tuần tự hóa và bản thân lớp hợp nhất (Tổng hợp) cũng khó khăn - cách tích hợp N đầu ra với cấu trúc không nhất quán là một thách thức về thiết kế. Việc phân chia nhiệm vụ phụ kém có thể dẫn đến thiếu sót hoặc nội dung trùng lặp.
3.3 Xác minh đối thủ (Xác minh đối thủ)
Logic cốt lõi là thử nghiệm. Đối với cùng một kết luận, nhiều tác nhân có thể thách thức nó từ góc độ "bác bỏ" và nó sẽ được coi là thông qua nếu nhận được hơn một nửa số phiếu bầu.
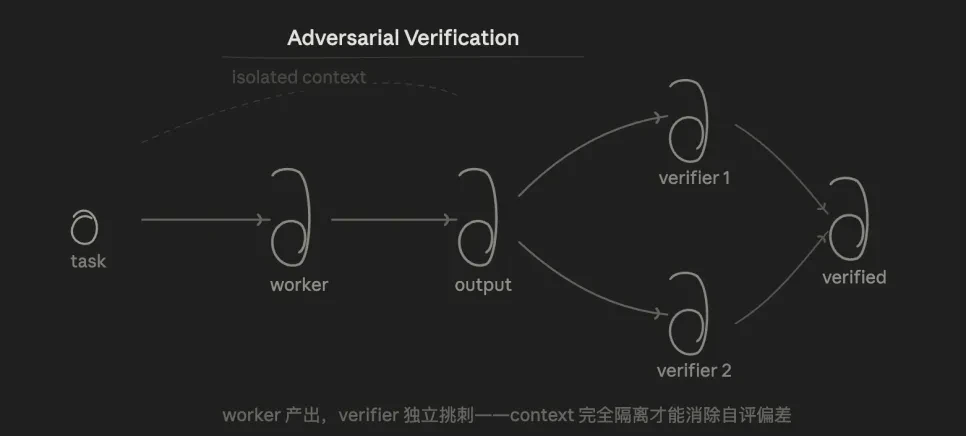
Ưu điểm là vì Người xác minh không biết Nhân viên. Ý tưởng chỉ xem kết quả về mặt cấu trúc sẽ loại bỏ thành kiến tự đánh giá khi "để người mẫu kiểm tra mã bạn đã viết".
Mô hình này giải quyết được một vấn đề khiến tôi băn khoăn bấy lâu nay: chúng ta thường nói chuyện với AI theo cách thông tục, nhưng AI có xu hướng trả lời theo mong đợi của bạn, điều này dễ dẫn đến "xu hướng xác nhận". Xác minh đối nghịch buộc AI phải tìm các phản ví dụ và xác minh dựa trên dữ liệu và thử nghiệm thay vì phục vụ cho ý tưởng của bạn.
Tuy nhiên, khi liên quan đến việc xác minh, nếu anh ta đưa ra phán đoán sai, anh ta sẽ thiên vị Công nhân và phục tùng Người xác minh. Vì vậy, tốt hơn là nên dựa trên những sự kiện có thể tái hiện lại hơn là dựa vào các ý kiến.
Đùa thôi, nếu bạn để AI tìm ra vấn đề, nó có thể tìm ra vấn đề vô tận, vì vậy bạn phải giới hạn ranh giới về nơi nó có thể tìm ra vấn đề.
3.4 Tạo & Lọc (Tạo & Lọc)
Logic cốt lõi là phân kỳ và sau đó hội tụ. Đầu tiên, các ứng cử viên quá mức được cố tình tạo ra, sau đó phiếu tự đánh giá được sử dụng để loại bỏ bản chất và chỉ đưa ra kết quả có độ tin cậy cao.

Thay vì để tác nhân đưa ra một câu trả lời "ok", tốt hơn là để nó tạo ra mười câu trả lời rồi sử dụng lớp xác minh để lọc. Vì vậy, lợi thế là sự đa dạng. Nhiều Trình tạo có thể sử dụng các chiến lược khác nhau và các từ gợi ý khác nhau để tạo ra các giải pháp khó dự đoán theo cách thủ công. Bước lọc giúp cho chất lượng đầu ra cuối cùng được cô đặc cao độ.
Điểm yếu là chất lượng phiếu tự đánh giá của Bộ lọc quyết định trực tiếp đến hiệu quả cuối cùng. Lỗi thiết kế phiếu tự đánh giá tương đương với việc loại bỏ toàn bộ quá trình
Các tình huống phù hợp là những tình huống không biết trước câu trả lời đúng, cần phải chọn phương án tốt nhất từ nhiều khả năng và cần có sự đa dạng rõ ràng.
Nó chỉ tương tự bề ngoài với Fanout-And-Synthesize: cả hai đều là "song song đa kênh → đầu ra đơn", điều này dễ bị nhầm lẫn nhất.
Sự khác biệt chính nằm ở ý định: Mỗi lượt Fanout xử lý một phần khác nhau của nhiệm vụ và kết quả là bổ sung cho nhau và tất cả các đường dẫn đều đóng góp khi hợp nhất; mỗi lần tạo và lọc xử lý cùng một tác vụ và kết quả mang tính cạnh tranh và hầu hết chúng sẽ bị loại bỏ khi hợp nhất. Cái trước là "câu đố" và cái sau là "cuộc thi sắc đẹp".
3.5 Chế độ giải đấu (Giải đấu)
Logic cốt lõi là loại bỏ tính cạnh tranh. Mỗi tác nhân N độc lập thực hiện công việc tương tự và bị loại từng người một thông qua so sánh từng cặp và cuối cùng giải pháp tối ưu được chọn.

Tôi đã thực hiện việc này theo cách thủ công trước đây - chạy hai hoặc ba phiên bản của cùng một mã thay đổi, sau đó để AI so sánh xem phiên bản nào tốt hơn. Bây giờ nó có thể được sắp xếp trực tiếp vào quy trình làm việc.
Ưu điểm nằm ở tính ổn định của đánh giá. So sánh theo cặp ("Cái nào tốt hơn, A hay B?") ổn định hơn nhiều so với xếp hạng tuyệt đối ("Tỷ lệ A") vì vấn đề sai lệch thang đánh giá được loại bỏ. Kết quả, sau nhiều vòng thi đấu, người chiến thắng cuối cùng có độ tín nhiệm cao.
Về bề ngoài, nó cũng tương tự như Tạo và lọc: cả hai đều chọn ra những ứng viên tốt nhất từ nhiều ứng viên. Điểm khác biệt chính nằm ở cơ chế tuyển chọn: Giải đấu sử dụng giám khảo theo cặp để so sánh các cặp, “để các thí sinh cạnh tranh với nhau”. Các phiếu tự đánh giá đáng tin cậy hơn khi chúng khó định lượng và các đánh giá có tính chất tương đối.
3.6 Chế độ vòng lặp (Vòng lặp)
Logic cốt lõi là Lặp lại thích ứng, tiếp tục thử, thu thập thông tin lỗi khi gặp trở ngại, thêm ngữ cảnh và thử lại cho đến khi đáp ứng các điều kiện chấp nhận.

Về cơ bản, nó đang chống lại tính ngẫu nhiên của AI: bạn càng cố gắng thì kết quả sẽ càng tốt. Nhưng một cách tiếp cận hoàn thiện hơn là kết hợp xác minh đối nghịch để mỗi chu trình được thực hiện với nhiều thông tin hơn thay vì chỉ dựa vào tính ngẫu nhiên.
Ưu điểm nằm ở khả năng xử lý các công việc với khối lượng công việc không xác định. Năm chế độ còn lại đều cho rằng ranh giới nhiệm vụ đã được xác định và Loop Until Done là chế độ duy nhất có thể xử lý "Tôi không biết phải làm bao nhiêu vòng"
Điểm yếu là nguy cơ tiềm ẩn vượt khỏi tầm kiểm soát - các điều kiện dừng được thiết kế kém sẽ dẫn đến một vòng lặp vô hạn. Tác nhân trong mỗi vòng là một bối cảnh mới và không thể tích lũy trạng thái xuyên vòng (trừ khi được ghi rõ ràng vào một tệp).
4. Cuộc chiến giữa kỹ năng của tôi và quy trình làm việc chính thức
Trước khi quy trình làm việc năng động ra đời, tôi đã đặc biệt thiết kế một bộ nghiên cứu chuyên sâu của riêng mình. Logic kỹ năng của tôi đại khái như thế này:
- Chỉ đưa ra một thông tin đơn giản (chẳng hạn như một tính năng mới của dự án)
- Hãy để AI tìm kiếm tất cả thông tin liên quan: tài liệu chính thức, mã nguồn, ý kiến thị trường
- Nén thông tin thành một bản tóm tắt có ý nghĩa
- Nhiều tác nhân Thực hiện phân tích đối nghịch về các vai trò và tạo báo cáo
- Tự động loại bỏ trùng lặp, vì tỷ lệ trùng lặp nội dung của nhiều tác nhân rất cao
Sau một thời gian sử dụng, tôi thấy nó rất hữu ích. Nhưng nó có một lỗ hổng cơ bản: thiếu sự hội tụ theo định hướng mục tiêu.
Và trong nhiều trường hợp, ngay cả khi đã thực hiện bước 5 chống trùng lặp, những thông tin có giá trị vẫn thường bị xóa vào thời điểm này. Nếu không sao chép, rất dễ để kỹ năng đưa ra cho bạn một bài viết dài 10.000 từ với thông tin đầy đủ, nhưng nó không trực tiếp cho bạn biết “việc này liên quan gì đến bạn và bạn nên làm gì”.
Tuy nhiên, nghiên cứu là để "ra quyết định", chính vì vậy nhiều kỹ năng chỉ có thể dừng lại ở bản thân việc nghiên cứu, được 80 điểm mà thiếu 20 điểm quan trọng nhất.
Đến mức sau khi AI hoàn thành nghiên cứu sơ bộ, nó vẫn cần tiếp tục suy nghĩ và đối thoại mười lần mới có thể đi đến kết luận thỏa đáng và toàn diện.
Quy trình làm việc năng động chính thức còn làm được gì nữa?
Qua một số thử nghiệm với các nhiệm vụ nghiên cứu phức tạp trong tuần này, tôi nhận thấy rằng quy trình nghiên cứu sâu được tích hợp sẵn của Claude Code (lưu ý rằng đó không chỉ là một kỹ năng mà là một mô-đun được biên dịch thành cc), so với kỹ năng của tôi, có thêm một số liên kết chính:
- Lớp phân tách câu hỏi: Nó không bắt đầu tìm kiếm trực tiếp, nhưng bắt đầu đặt câu hỏi trước, chia câu hỏi của tôi thành nhiều câu hỏi phụ: Bạn thực sự muốn tìm hiểu điều gì? Vấn đề này có liên quan gì đến bạn? Những khía cạnh nào đáng được nghiên cứu thêm? Tôi đã bỏ qua bước này trước đây.
- Đánh giá độ tin cậy: Đánh giá mức độ giả mạo của từng thông tin, tương tự như điểm thẩm quyền trong SEO truyền thống - nguồn có đáng tin cậy không? Làm thế nào về số lượng trích dẫn? Đây là một liên kết mà tôi chưa bao giờ nghĩ đến việc thêm vào trước đây.
- Xóa chéo thay vì hợp nhất trung bình: Cách tiếp cận trước đây của tôi là chọn tất cả các kết luận như nhau nên tài liệu rất lớn. Quy trình làm việc năng động sẽ thực hiện nhiều phiếu bầu của tác nhân cho mỗi kết luận và những phiếu bầu không đủ sẽ bị xóa thay vì chỉ được hợp nhất.
- Đầu ra hướng đến mục tiêu: Báo cáo cuối cùng không phải là một đống thông tin mà là một nhận định và đề xuất dựa trên các mục tiêu ban đầu của bạn. Chìa khóa để đạt được điều này nằm ở khả năng đặt trước của nó trong việc lên lịch cho nhiều đại lý phụ. Lý do khiến kỹ năng của tôi trước đây dễ bị thiếu định hướng mục tiêu cuối cùng là do sự suy giảm trọng lượng mệnh lệnh sau lượng thông tin khổng lồ.
Các cơ chế này giải quyết vấn đề gì?
Nó nhằm vào một số vấn đề điển hình của AI khi thực hiện các nhiệm vụ dài:
Trôi lệch mục tiêu: Nhiệm vụ ở trạng thái tốt lúc đầu, nhưng đến giữa nó không còn biết mình đang làm gì và nhịp điệu được khôi phục lại ở cuối - tương tự như con người đi lang thang trong lớp. Nhiệm vụ càng dài thì nó càng trở nên rõ ràng.
Dừng sớm: Khi gặp khó khăn, AI dừng lại khi tưởng rằng đã "hoàn thành" nhưng thực tế tiêu chí chấp nhận hoàn toàn không được vượt qua.
Ô nhiễm bối cảnh: Khi một tác nhân duy nhất thực hiện các nhiệm vụ phức tạp, một số lượng lớn lời nhắc ở phía trước sẽ nén không gian thực thi tiếp theo. Cách tốt hơn là kiểm soát lời nhắc trước trong phạm vi vài kilobyte và sử dụng nhiều tác nhân để chia sẻ ngữ cảnh.
Thành kiến đầu ra: AI có xu hướng trả lời theo mong đợi của bạn và các câu hỏi nói có nhiều khả năng kích hoạt câu hỏi này hơn.
Quy trình làm việc năng động giải quyết bốn vấn đề này theo cách có cấu trúc: tự động thêm các chỉ báo chấp nhận để ngăn chặn việc dừng sớm; bối cảnh cách ly song song; xác minh đối kháng để bù đắp sai lệch đầu ra; giải quyết từng lớp vấn đề và buộc AI phải hiểu mục tiêu trước khi hành động.
V. Tóm tắt
Cuối cùng, với tư cách là một nhà nghiên cứu lâu năm, tác giả rất ngạc nhiên trước cơ chế CC mới này. Sáu chế độ tích hợp của nó - định tuyến, phân tách và hợp nhất, xác minh đối thủ, lọc thế hệ, chiến dịch vô địch và vòng lặp - đáp ứng nhu cầu lập kế hoạch của hầu hết các nhiệm vụ nghiên cứu phức tạp.
Tôi không còn cần phải thiết kế lịch trình tổng đài viên theo cách thủ công cũng như không cần phải tự mình thực hiện sao chép và xác thực chéo. Tất cả những điều này đều được biên soạn vào chính quy trình làm việc.
Và anh ấy đặc biệt thích hợp để suy nghĩ về việc thiếu thông tin và khám phá các vấn đề phát triển, bởi vì việc lập lịch trình đa tác nhân tự nhiên + việc phân chia các mục tiêu nhiệm vụ cho phép anh ấy cải thiện tính linh hoạt của mình. Trên thực tế, AI ngay từ 3 năm trước đã làm rất tốt việc giải quyết các vấn đề nhỏ rất rõ ràng với các ràng buộc theo từng lớp. Tuy nhiên, sự thay đổi về chất thực sự của AI nằm ở tính linh hoạt của nó. Đây là nơi các đối thủ cạnh tranh của anh ấy đã đi từ những mã đơn giản đến việc trở thành đặc vụ thực sự, từ giải quyết vấn đề ở trạng thái rắn đến thích ứng với mọi vấn đề.
Vì vậy, Quy trình làm việc động không phải nhằm mục đích "các cuộc trò chuyện riêng lẻ thông minh hơn" mà là về việc tự cấu trúcquy trình nghiên cứu.
Nghiên cứu ban đầu yêu cầu tôi phải bắt đầu hơn chục cuộc trò chuyện độc lập giờ đã giảm xuống còn 3-4 lần. Mặc dù mức tiêu thụ Token tương ứng đã tăng lên hàng chục lần.
Vậy tại sao chúng ta lại cần 3-4 lần? Tôi nghĩ nguyên nhân sâu xa nằm ở sự khác biệt trong những nhu cầu này.
Đầu tiên là sự nghiêm ngặt của cơ chế xác minh. Tôi chủ yếu nghiên cứu các công nghệ mới trên blockchain. Đối với nhiều thứ, các tài liệu chính thức bị tụt lại phía sau. Có các mã nguồn mở, giao dịch trực tuyến và các dữ liệu khác đáng tham khảo hơn. Hiện tại, AI mặc định sử dụng các tài liệu chính thức thay vì xác minh thực tế.
Thứ hai là Suy nghĩ chuyên sâu hoàn toàn xuyên biên giới. Mặc dù điều này có thể được giải quyết thông qua các cài đặt trước của quy trình công việc (các tác nhân con được xác định trước có nhiều kích thước khác nhau) để suy nghĩ về cùng một vấn đề. Tuy nhiên, điều AI giỏi vẫn là mô hình tư duy chủ đạo và nó hơi thiếu cơ sở dữ liệu rất mới, rất sâu sắc và thiếu dữ liệu.
Thứ ba là Thiết kế và xác minh giải pháp. Ý nghĩa của giải pháp không phải là đề xuất mà là kiểm chứng và hỗ trợ. Nó dựa vào việc đo lường các cơ chế, đầu vào và chi phí hiện có. Tất nhiên, nếu AI được đào tạo bài bản thì nó có thể làm tốt hơn, nhưng điều này đi ngược lại tính phổ quát.
Bước cuối cùng là Cô đọng thông tin cuối cùng. Điều này đòi hỏi phải quay trở lại mức độ hiểu biết của người nghe về thông tin. Một số người không có nền tảng và cần sự thể hiện hình ảnh nhân cách hóa của bạn, trong khi một số khán giả cần bạn gây ấn tượng với họ bằng một câu nói ~.
