
如何用克勞德的动态工作流程做深入研究
如何构建我和AI的互补關係。

過去三年來,我在AI的支援下進行了工業研究,我建立了一系列的技巧和辅助系統,以整理資訊的過程,總計,連接,驗證,沉淀。
直到這周才通過克勞德代碼的动态工作流程,"人們不戰鬥偉大時代"這個詞的真正含义才被理解。
再想想: 如何构建我和AI的互补關係。
一. 首先研究的陷阱
技術研究實際上是陷阱(對人和AI都是陷阱), 所以現在該了解回歸的目的了。
所以AI不夠好 因為從關注和關聯的角度他將比人類更困在目前的資訊量中。
當然,AI已經夠好,可以完成尋找、总结和避免失蹤的任務。
雖然我過去半年來沒有宣傳多少。
面對上星期的克勞德代碼 动态工作流 我想和他一起下去 看看他的缺省能力是否超出我的能力。
什么是动态工作流
动态工作流的核心線是:在任務完成前, AI會自動設計工作流程。
這和我們以前用的"計劃模型"和"技能"根本不同 計畫模式是拆掉任務, 可能會加上接受指示器(對研究很重要)。
然而,动态工作流程自動包含接受的邏輯、收縮結果和對話以驗證這些事。
扳機很簡單, 直接在cc/ 深度研究中nbsp; (n);提供一些研究樣本和存取資訊就足夠了, 如果光是使用动态工作流程的能力是暗示或直接超碼。
三. 內含6种工作流程模式
動力工作流程的底部是官方概述的六個核心移動模式。
事實上, 如何合身。
3.1 & nbsp; 路由模式( 分类- And- Act)
工作首先由代理确定,然后分配到最合适的專業 & nbsp;代理 & nbsp;快 核心邏輯是:路由選擇的逻辑,而不是平行或迭代。 一個任務只遵循一條路,而另一條路完全不執行。
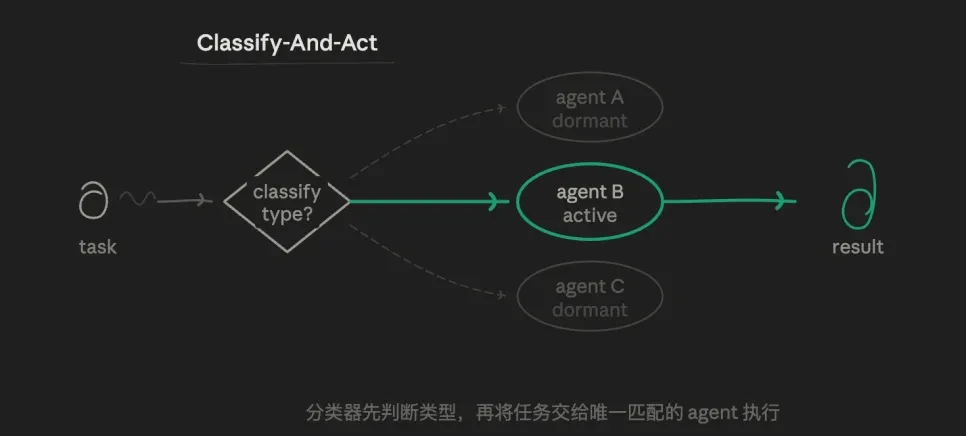
例如,我可以從3個預設的子代理角色開始: 分析嚴格的數據分析 antent,一個善於寫作antent的輸出,一個專門尋找漏洞的挑戰。 讓路由器來判斷目前的子任務是為誰而設的, 而不是讓一個單一的包。
這個模型的價值是它精確而经济,每一個代理的提示可以高度獨立,不受其他目標的影響,導致垂直深度探索. token的消费量最低,反应最快。 責任分明。
也存在重大缺陷。
3.2 分拆合併( Fan- out & amp; 合併)
這也是我最常用的模型 核心邏輯是平行加整合 工作分成 N 獨立的子工作, 同步執行, 完成後再整合 。

其优点是速度和孤立。 總的時間是關於最慢的提交,而不是全部的總和. 每一份呈文都是獨立的,不受干涉,不因一份呈文的噪音而污染其他呈文。
弱點是信號成本是系列數的三倍, 分工作分工不善,造成工作疏忽或重复。
3.3 & nbsp; 反驗證( 多元驗證)
核心邏輯是:測試, 多重 & nbsp 表示同一結論;代理 & nbsp;從"反對"的角度看,票數超過一半。
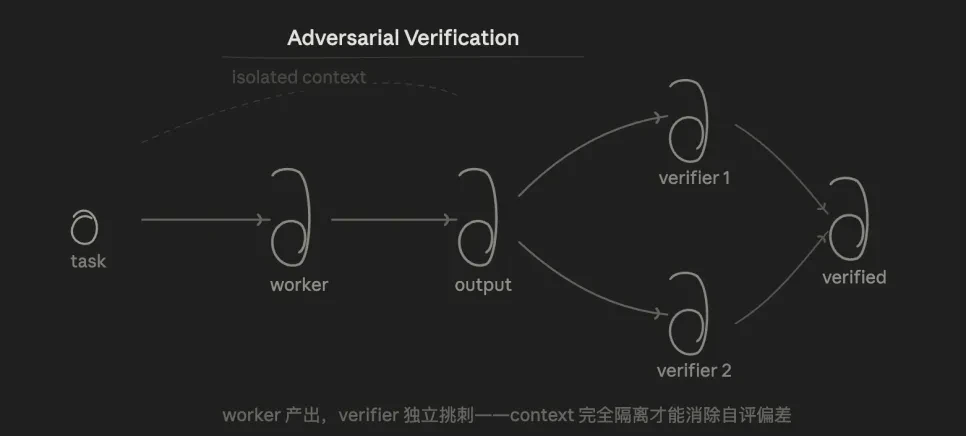
其優點是,因為Veriver不知道Walker的想法, 它只看結果。
這個模式解決了一個长期存在的問題:我們常以口語方式與AI談話, 藉由面對驗證,迫使AI尋找反向例子。
但是,為了確認這一點,如果他做出錯誤的判斷,他會帶他去威維爾 所以偏好選擇的基礎是可追溯的事實而不是觀點。
我開玩笑的說 如果你讓AI找到問題 他可以一直這樣 所以你必須限制他發現問題的界限。
3.4 生成和滤波器 (Generate & amp; Filter)
核心邏輯是:It而散,后降我不知道 首先,你故意造成 太多的候選人, 然後你逐步淘汰它 和rubritic, 你保持的輸出 高信任度。

而不是代理輸出一個"好"的答案, 更好的是產生10個, 然后用憑證層來过滤它。 因此,優點在于多元性。 多個產生器可以使用不同的策略, 不同的提示。
弱點是 Filter 的 數值質量直接決定了終點效果, 數值設計錯誤是整個过程的結束
相當適合的情況是。
幻想和合成就像表面「更多道路平行。
关键是..意向(a) Fanout的每條路涉及任務的不同部位, 第一個是拼圖,第二個是選美。
3.5 比賽
核心逻辑是竞争性淘汰。 N 代理單獨做同樣的事, 採用 & nbsp; 配對 & nbsp; , 比較回合淘汰, 最後選擇最佳的解決方案 。 nbsp; (N);

這個是我手動做的,同一個密碼會改變兩個或三個版本,使AI比對的要好. 它現在可以在工作流程中直接排列。
其优点在于判斷穩定性. 兩種對比(「A」和「B」誰更好? )比絕對評分(「A」評分)更穩定, 結果是多輪比賽。
其相似于生成法: 兩者都是從多位候選人中选出的。 關鍵的區別是選舉机制: 比賽, 更可靠。
3.6 圈
核心邏輯是:從适应——不断收集虚假信息,补充上下文,直至符合接收条件。

這與人工智能的隨機性是相矛盾的, 但將對峙證實结合起来, 讓每個周期都能得到更多的資訊。
其优点在于能處理工作, 其他五種型號都假設任務邊界是固定的, & nbsp; Loop 直到 Done 是唯一能處理"不知道有多少子彈"的型號
弱點是失去控制的潜在風險, 每輪動因子是完全新的上下文,不能累积跨輪狀態(除非在檔案中清楚寫出) 。
四、我的自殺和正式的蝙蝠
在动态工作出來前,我設計了自己的一套 & nbsp; deep-research 我的技術邏輯可能是:
- 只有一個簡單的訊息( 例如專案的新功能 )
- 讓 AI 搜尋所有相關資訊:官方檔案、源碼、市場意見
- 將資訊压缩成有意义的摘要
- 多重代理角色以反分析及生成報告
- 由于多代理內容的重複率高, 自動重複
我花了好一陣子才覺得有用。但是它有一個根本的缺陷:缺乏面向目標的增長。
而且很多次,即使有第五步的重量級,在這時他常常移除有价值的信息,如果它不夠重,技術就特别容易給你長長的,完整的文字,但不告訴你,"這和你有什麼關係?"。
許多技術都停留在研究本身。
依據創用CC授權使用。
官方的动态工作是做什么的
我發現Claude Code的內建 & nbsp; Deep Research & nbsp; Workstreams(不只是技術
- 拆解問題:它不只是開始尋找, 而是從問問問題開始, 這跟你有什麼關係? 哪些維度值得探索? 我以前做過。
- 可信度评估根據創用CC授權使用 有多少參考? 那是我沒想到的。
- 交叉刪除而不是平均合并:我曾經平均選取所有結論, 動態的工作流程對每個結論投了票。
- 面向目標的輸出最後報告不是一堆資訊, 其關鍵在于他预先設置的移動多個孩子的能力,而我之前有技術的理由是,我很容易沒有終端导向,因為在大量信息之後,我不知道我在找什麼指令重量下降我不知道。
這些机制解決了什麼
這是關於AI做長期任務的一些典型問題:
目標漂移任務以良好的狀態開始, 任務越長 越明顯。
早點停下:跑得快,AI認為他已經結束了,他停止了,實際上沒有人接受。
环境污染: 單位代理執行複雜的工作, 大量預置位置會壓縮之後的執行空間 。 最好能將預期控制在幾k以內。
輸出偏差AI往往跟隨你的期望。
動力工作流程以結構的方式處理這四種問題:自動接收指示器防止过早停止; 平行地隔離上下文; 反驗證抵消輸出偏差; 以及解除層層限制 AI在行動前理解目標。
摘要
最后,作為一位永久研究者,CCC的新机制印象深刻的是,它嵌入的六種模式——路由選擇,分離,反授權,过滤,冠軍競選,環球流通——涵盖了最複雜的研究任務的行動要求。
所以我不需要手動設計授權移動 也不需要自己做權重和交叉檢查 它們都編程在工作流程中。
他尤其適合思考資訊缺乏與發展問題的探索, 因為自然藥物運動與任務目標的分離。
所以,动态工作流程,动态工作流程 不是"更聰明的單向對話",只是..研究程序本身是结构化的。
我不得不開始一打獨立對話 現在我降為3比4 雖然Token的消费量增加了好幾倍。
那為什麼還要三四次& nbsp; 我想根本原因就是需求的不同。
第一:认证机制的严重程度我主要研究區塊鏈的新技术, 很多事情, 官方文件都落在后面。
第二全面跨界深思雖然可以透過工作流程預置(subAgent, 但AI善于主流思考模式。
第三:溶液设计和驗證雖然這與互操作性是相悖的, 但這並不意味著要提出它, 而是要證實它, 支持它。
最后极致信息丰富有些人沒有背景, 需要你的形象, 而其他人則需要你的話來打動他。
