
Cara melakukan studi mendalam dengan Aliran Kerja Dinamik Claude
APA KEDALAMAN PENELITIAN YANG HARUS DILAKUKAN ORANG-ORANG DI ERA AI, DAN BAGAIMANA MEMBANGUN HUBUNGAN YANG SALING MELENGKAPI ANTARA AKU DAN AI。

Dalam tiga tahun terakhir, saya telah melakukan penelitian industri dengan dukungan AI, dan saya telah membangun serangkaian keterampilan dan sistem pembantu untuk memilah penyaringan informasi, penjumlahan, koneksi, validasi, sedimentasi。
Tidak sampai minggu itu pergi melalui aliran kerja dinamis Claude Code bahwa arti sebenarnya dari frasa "orang tidak melawan masa-masa besar"。
PIKIRKAN LAGI: APA KEDALAMAN PENELITIAN YANG HARUS DILAKUKAN ORANG-ORANG DI ERA AI DAN BAGAIMANA MEMBANGUN HUBUNGAN YANG SALING MELENGKAPI ANTARA AKU DAN AI。
Dimulai dari jebakan penelitian
PENELITIAN TEKNIKAL YANG DILAKUKAN OLEH AHLI TEKNIK ADALAH, PADA KENYATAANNYA, SEBUAH PERANGKAP (BAIK UNTUK ORANG MAUPUN UNTUK AI) DAN, SETELAH ITU, BANYAK SEKALI INFORMASI YANG DITERIMA SEJAK AWAL PENELITIAN, DENGAN SEMAKIN BANYAKNYA PERSPEKTIF DAN KESIMPULAN YANG SEMAKIN SAMAR. JADI SEKARANG SAATNYA UNTUK MEMAHAMI TUJUAN UNTUK KEMBALI SENDIRI。
DAN ITULAH SEBABNYA AI TIDAK CUKUP BAIK, KARENA DARI SUDUT PANDANG PERHATIAN DAN ASOSIASIDia akan lebih terjebak daripada manusia dalam jumlah informasi saat ini dan lemah dalam benar-benar berharga koneksi lintas-pembatasan。
Tentu saja, AI cukup baik untuk dapat melaksanakan tugas mencari, menyimpulkan, dan hanya menghindari hilangnya detail。
meskipun saya belum memberikan banyak publisitas dalam enam bulan terakhir, saya telah mencari dan meneliti hampir semua bidang utama industri, dan masukan ini didukung oleh sistem penelitian mendalam saya sendiri。
Dan dalam menghadapi Claude Code minggu lalu di baris, Dynamic Workflows, aku ingin turun bersama satu sama lain dan melihat apakah kekuatan bawaannya di luar kemampuanku。
Apa itu Aliran Kerja Dinamis
Garis inti dari Aliran Kerja Dinamik adalah:SEBELUM MISI DILAKUKAN, AI AKAN SECARA OTOMATIS MERANCANG ALUR KERJA APA YANG SEHARUSNYA DIGUNAKAN UNTUK TUGAS TERSEBUT DAN KEMUDIAN MEMULAI EKSEKUSI。
Hal ini secara mendasar berbeda dengan model "plan" dan "skill" yang biasa kita gunakan. Model rencananya adalah meruntuhkan tugas, tetapi tidak selalu sesuai dengan alur kerja yang masuk akal. Hal ini dimungkinkan untuk menambahkan indikator penerimaan (yang penting untuk Penelitian) dengan petunjuk Anda, dan Anda hanya akan lebih siap untuk mengatur beberapa aturan harness jika Anda memiliki satu。
Namun, aliran kerja dinamis secara otomatis menggabungkan logika penerimaan, konstriksi hasil, dan konfrontasi untuk memverifikasi hal-hal ini。
pemicunya sederhana, langsung dalam cc/deep-research ia kemudian akan mencukupi untuk menyediakan beberapa templat penelitian dan informasi akses, dan jika kemampuan untuk menggunakan alur kerja dinamis saja adalah petunjuk atau ultracode langsung, sebelum digunakan, token mengkonsumsi sekitar puluhan kali lebih banyak。
/ III. Mode aliran kerja enam inline
bagian bawah aliran kerja dinamis adalah enam pola pergerakan inti yang secara resmi dirangkum, itulah sebabnya lebih kuat daripada dialog/agen/skill biasa。
Faktanya, hanya ada dua masalah inti di balik enam model: bagaimana tugas dapat dipecahkan? Bagaimana sesuai。
Mode rute (Klasify-And-Act)
tugas pertama diidentifikasi oleh agen dan kemudian didistribusikan ke yang paling sesuai khusus & nbsp;agengia Lakukan. Logika intinya adalah:Log Logika pemilihan rute, tidak paralel atau iteratif. Salah satu misi hanya mengikuti satu jalur, dan jalan lain benar-benar non-implementasi。
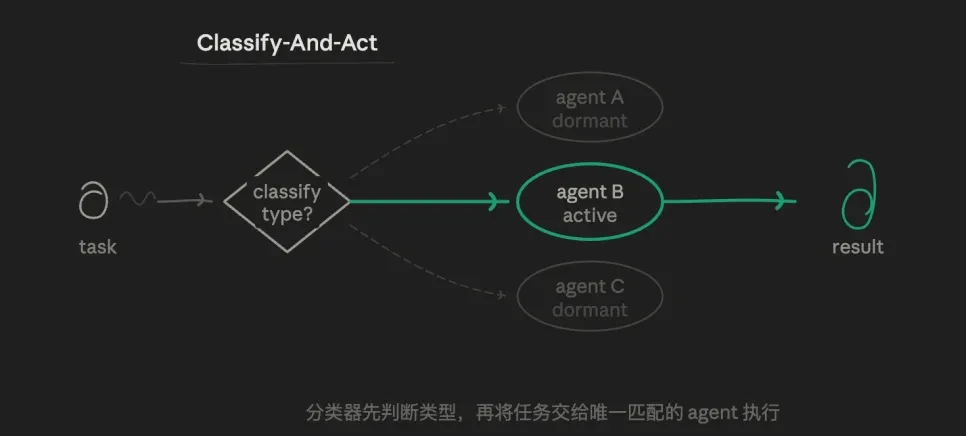
sebagai contoh, saya dapat memulai dengan tiga peran subagen preset: analisis analisis data yang rigorous antent, output yang baik dalam menulis antent, tantangan yang didedikasikan untuk menemukan celah. ia membiarkan router menilai siapa sub-task saat ini adalah untuk, daripada membiarkan gerombolan individu。
nilai dari model ini adalah bahwa itu tepat dan ekonomis, dan setiap petunjuk agen dapat sangat independen dan bebas dari target lain, mengarah ke eksplorasi kedalaman vertikal. token memiliki konsumsi terendah, respon tercepat. jalur tanggung jawab sangat jelas。
Ada juga kelemahan signifikan dan kapasitas lemah untuk menangani tugas-tugas yang mengaburkan perbatasan (seperti " masalah teknis dan akun"。
3.2 Pisahkan amalgasi (Fan-out & Cantuman)
INI JUGA MODEL PALING UMUM SAYA, DAN LOGIKA INTI ADALAH PARALEL DITAMBAH KONSOLIDASI. TUGAS-TUGAS DIBAGI MENJADI N SUB-TUGAS TERPISAH, BERJALAN SECARA BERSAMAAN DAN KONSOLIDASI MEREKA SETELAH SEMUA SELESAI。

keuntungannya adalah kecepatan dan isolasi. waktu total adalah tentang penyerahan paling lambat, bukan jumlah dari semua. ketundukan masing-masing adalah subjek independen, tanpa gangguan, dan tidak mencemari penyerahan yang lain karena kebisingan satu penyerahan。
Kelemahlemahan adalah bahwa biaya token adalah tiga kali lipat jumlah seri, dan lapisan konsolidasi itu sendiri sulit - bagaimana mengintegrasikan output dengan struktur jalan N yang tidak konsisten adalah tantangan desain. Kemiskinan pembagian sub-tasks menyebabkan omisi atau duplikasi cakupan。
3,3 & nbsp; Penanggulangan Kembali (Penerimaan Kembali)
Logika intinya adalah:Uji, multiple & nbsp untuk kesimpulan yang sama;agengia Dari Ørefuting" sudut pandang, itu lebih dari setengah suara。
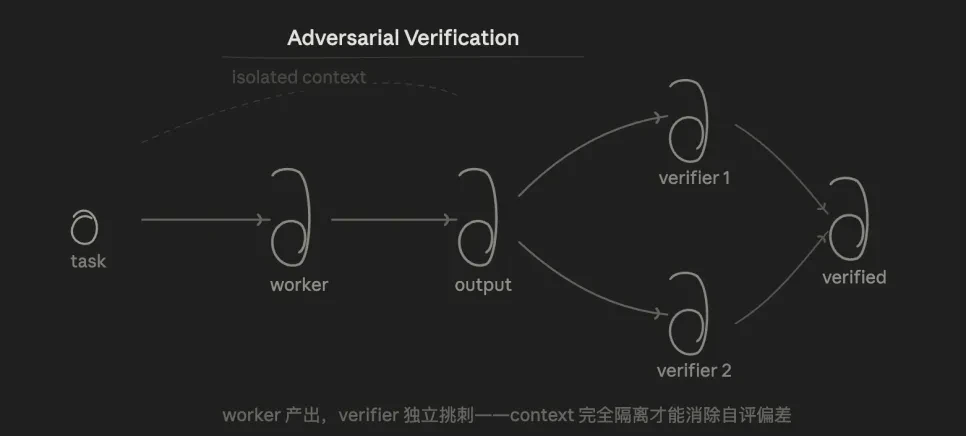
Keuntungannya adalah bahwa, karena Verifier tidak tahu apa yang Walker pikirkan, itu hanya melihat hasil, dan secara struktural menghilangkan bias evaluasi diri dalam "Biarkan model memeriksa kode yang ia tulis."。
POLA INI MEMECAHKAN MASALAH LAMA-BERDIRI: KITA SERING BERBICARA DENGAN AI SECARA LISAN, TETAPI AI CENDERUNG MENANGGAPI HARAPAN ANDA, DAN MUDAH UNTUK "MENGAKUI BIAS." DENGAN MENGHADAPI VALIDASI, MEMAKSA AI UNTUK MENCARI CONTOH TERBALIK, UNTUK MENGUJINYA ATAS DASAR DATA DAN EKSPERIMEN, DARIPADA PADA ANDA SENDIRI。
Tapi, untuk memverifikasi ini, jika dia memberikan penilaian yang salah, dia akan membawanya ke Verifier. Jadi pilihan yang disukai didasarkan pada fakta-fakta yang repertoar daripada pada sudut pandang。
AKU HANYA BERCANDA UNTUK MENGATAKAN BAHWA JIKA ANDA MEMBIARKAN AI MENEMUKAN MASALAH, DIA BISA MELAKUKANNYA SEPANJANG WAKTU, JADI ANDA HARUS MEMBATASI BATAS DI MANA IA MENEMUKAN MASALAH。
Penjanaan dan Penapisan (Generate & Penapis)
Logika intinya adalah:Ini akan menyebar, kemudian akan turunaku tidak tahu. pertama, anda sengaja membuat jumlah kandidat yang berlebihan, kemudian anda fase keluar dengan rubric, dan anda menjaga output percaya diri tinggi。

Alih-alih memiliki agen output a " fine" jawaban, lebih baik untuk menghasilkan sepuluh, kemudian menyaringnya dengan lapisan sertifikasi. Keuntungannya oleh karena itu terletak pada keragaman. Multiple Generator Adouard dapat menggunakan strategi yang berbeda, petunjuk yang berbeda, solusi output yang secara artifisial sulit untuk mengantisipasi, dan langkah penyaringan memungkinkan konsentrasi kualitas keluaran akhir yang tinggi。
Kelemahannya adalah massa rubrik Filter secara langsung menentukan efek akhir, dan kesalahan desain rubrik adalah akhir dari seluruh proses
Skenario yang sesuai adalah situasi di mana jawaban yang benar tidak diketahui di muka, di mana keuntungan perlu diambil dari berbagai kemungkinan, dan di mana ada kebutuhan yang jelas akan keragaman。
Fanout-And-Syntheize sama seperti permukaanJalan yang lebih paralel, keluaran tunggal" adalah yang paling mudah membingungkan。
Perbedaan kuncinya adalah..Keganjilan(a) Setiap jalan di Fanout berurusan dengan bagian misi yang berbeda-beda, hasilnya adalah pelengkap dan semua jalur berkontribusi untuk penggabungan; setiap jalan di Fanout berurusan dengan tugas yang sama, hasilnya menjadi kompetisi dan sebagian besar merger dibuang. Yang pertama adalah teka-teki, yang kedua adalah kontes kecantikan。
Turnamen Uibah 3.5
Logika inti adalah tahap kompetitif. Agen-agen N melakukan hal yang sama dengan mereka sendiri, dengan mengadopsi & nbsp; pairwise dengan membandingkan round-by-round fase-out, akhirnya memilih solusi terbaik.

INI YANG SAYA LAKUKAN SECARA MANUAL -- KODE YANG SAMA MENGUBAH DUA ATAU TIGA VERSI, DAN MEMBUAT AI LEBIH BAIK DARI YANG BENAR. SEKARANG DAPAT DIATUR SECARA LANGSUNG DALAM ALUR KERJA。
KEUNTUNGANNYA ADALAH MENILAI STABILITAS. DUA KONTRAS ( "A" DAN "B" YANG LEBIH BAIK?") JAUH LEBIH STABIL DARIPADA PERINGKAT ABSOLUT ( "A" RATING), KARENA MEREKA MENGECUALIKAN DRIFT KRITERIA PERINGKAT. HASIL INI TELAH BEBERAPA PUTARAN KOMPETISI DAN PEMENANG FINAL MEMILIKI KREDIBILITAS TINGGI。
Ini mirip dengan Genation-And-FilterKeduanya dipilih dari beberapa kandidat. Perbedaan utamanya adalah mekanisme seleksi: Turnamen, dengan perbandingan dua dan dua, adalah "menggabungkan kandidat." Bila rubrik sulit untuk mengkuantifikasi dan menghakimi adalah oleh relatif alam, hal ini lebih dapat diandalkan。
Gelung anime 3.6
Logika intinya adalah:Dari PenyesuaianKebohongan — Berkelanjutan berupaya mengumpulkan informasi palsu, melengkapi konteksnya, sampai kondisi penerimaan terpenuhi。

HAL INI PADA DASARNYA TERHADAP KEACAKAN AI: MENCOBA LEBIH BANYAK, SELALU MENABRAK HASIL YANG LEBIH BAIK. NAMUN AKAN LEBIH MATANG UNTUK MENGGABUNGKAN SERTIFIKASI KONFRONTASI DAN MEMUNGKINKAN SETIAP SIKLUS DIIMPLEMENTASIKAN DENGAN LEBIH BANYAK INFORMASI, DARIPADA SEKADAR ACAK。
Keuntungan tersebut terletak pada kemampuan untuk menangani tugas dengan beban kerja yang tidak diketahui. Lima model lainnya menganggap bahwa batas misi adalah tetap, Gelung Sampai Selesai satu-satunya yang dapat menangani "tidak tahu berapa banyak putaran"
kelemahlemahan adalah potensi risiko kehilangan kendali — kondisi berhenti tidak dirancang dengan baik untuk beredar tanpa batas. setiap putaran anent adalah konteks yang sama sekali baru yang tidak dapat mengumpulkan keadaan lintas roda (kecuali ditulis dengan jelas dalam berkas)。
Aku tak tahu apa-apa
aku merancang set saya sendiri & nbsp sebelum kerja dinamis keluar; deep-research logika keterampilanku mungkin ini:
- Hanya satu pesan sederhana (misalnya fitur baru pada proyek)
- AI PENCARIAN AI SEMUA INFORMASI YANG RELEVAN: BERKAS RESMI, KODE SUMBER, OPINI PASAR
- Mampatkan informasi ke dalam jumlah yang berarti
- berperan agen ganda untuk menganalisa dan menghasilkan laporan
- secara otomatis secara otomatis berat karena tingkat pengulangan tinggi konten agen ganda
Aku butuh waktu untuk menemukannya berguna。Tapi itu memiliki kelemahan mendasar: kurangnya pertumbuhan berorientasi tujuan。
dan berkali-kali, bahkan jika ada kelas berat langkah kelima, pada saat ini, ia sering menghapus informasi berharga, dan jika tidak cukup berat, sangat mudah untuk keterampilan untuk memberikan anda teks panjang, penuh, tapi tidak memberitahu anda, " apa hubungannya ini dengan anda?"。
namun, untuk tujuan \"pembuatan keputusan\", inilah mengapa banyak keterampilan berhenti pada penelitian itu sendiri, dengan 80 poin, tetapi kurang dari 20 poin paling kritis。
SEJAUH INI, SETELAH SELESAINYA PENELITIAN, AI PERLU MELANJUTKAN 10 REFLEKSI DAN DIALOG UNTUK MENCAPAI KESIMPULAN YANG MEMUASKAN DAN MENYELURUH。
Apa pekerjaan dinamis resmi itu
Melalui beberapa percobaan dengan misi penelitian kompleks minggu ini, saya menemukan bahwa Claude Code's built-in & nbsp; Deep Research & nbsp; Workstreams (bukan hanya keterampilan, tetapi kompil modul tertanam dalam cc) memiliki beberapa kunci link ke keterampilan saya sendiri:
- Masalah GangguanIni tidak hanya mulai mencari, tapi dimulai dengan mengajukan pertanyaan dan memecah pertanyaan saya menjadi sub-pertanyaan: apa yang Anda benar-benar ingin tahu? Apa hubungannya ini denganmu? Dimensi apa yang layak dijelajahi? Aku pernah melakukan ini sebelumnya。
- Penilaian kredibilitas• MENGASUMSIKAN PER SEPOTONG INFORMASI UNTUK SUMPAH PALSU, PERINGKAT YANG BERWIBAWA MIRIP DENGAN YANG TERDAPAT DALAM SEO TRADISIONAL — APAKAH SUMBERNYA KREDIBEL? BERAPA BANYAK REFERENSI? ITULAH YANG SAYA TIDAK MENGHARAPKAN UNTUK MENAMBAHKAN。
- Hapus salib dari luaraku biasa memilih semua kesimpulan rata-rata, jadi filenya besar. pengumpulan karya dinamika menghasilkan suara pada setiap kesimpulan, dengan suara yang tidak cukup dihapus dan tidak digabung begitu saja。
- Keluaran berorientasi Targetlaporan terakhir bukan setumpuk informasi, tapi sebuah penilaian dan proposal di sekitar tujuan asli anda. kunci untuk ini adalah kemampuan pra-set nya untuk memindahkan beberapa anak, dan alasan mengapa saya telah terampil sebelumnya adalah bahwa mudah bagi saya untuk tidak memiliki orientasi berorientasi akhir, karena setelah massa informasi, saya tidak yakin apa yang saya cariTolak berat perintahAku tidak tahu。
Apa yang telah diselesaikan mekanisme ini
INI TENTANG BEBERAPA PERTANYAAN TENTANG AI MELAKUKAN MISI PANJANG:
Target hanyutMisi ini dimulai dengan baik, tidak tahu harus berbuat apa di tengah, dan diakhiri dengan irama baru — pelajaran bagi manusia. Semakin lama misi, semakin jelas。
Berhenti lebih awalBERLARI KERAS, MENURUT AI DIA SUDAH SELESAI, DAN DIA BERHENTI, DAN PADA KENYATAANNYA TIDAK ADA PENERIMAAN。
Polusi Konteks KABangent individu melakukan tugas kompleks, dan sejumlah besar pre-posisi memampatkan ruang eksekusi selanjutnya. cara yang lebih baik untuk menjaga pre-prompt dalam beberapa k dan menyebarkan konteks di antara berbagai pihak。
Bias output ufukAI CENDERUNG MENGIKUTI HARAPAN ANDA, DAN LEBIH MUDAH UNTUK MENGAJUKAN PERTANYAAN LISAN UNTUK MEMICUNYA。
ALIRAN KERJA DINAMIS YANG TERKOMODIFIKASI MENGALAMATKAN KEEMPAT ISU INI DENGAN CARA TERSTRUKTUR: INDIKATOR PENERIMAAN-OTOMATIS UNTUK MENCEGAH PENGHENTIAN PREMATUR; ISOLASI PARALEL KONTEKS; COUNTER-VALIDATION OFFSET OUTPUT BIAS; DAN MEMBONGKAR LAPISAN BATASAN AI MEMAHAMI TARGET SEBELUM TINDAKAN。
Ringkasan
Akhirnya, sebagai peneliti permanen, mekanisme baru untuk CCC terkesan oleh fakta bahwa enam model yang tertanam di dalamnya — pemilihan rute, pemisahan, anti-sertifikasi, penyaringan, kampanye kejuaraan, sirkulasi Loop — mencakup persyaratan pergerakan sebagian besar misi penelitian yang rumit。
jadi saya tidak perlu merancang gerakan angent secara manual, dan saya tidak perlu melakukan pemberatan dan pemeriksaan silang sendiri, yang semua diprogram ke dalam alur kerja itu sendiri。
Dan dia terutama ditempatkan dengan baik untuk berpikir tentang kurangnya informasi dan eksplorasi isu-isu perkembangan, karena pemisahan gerakan doagensi alami ditambah tujuan misi telah membesarkan dia lagi dalam hal interoperabilitas, yang, tiga tahun yang lalu, AI telah dilakukan dengan baik dalam mengatasi hanya sangat jelas dan kecil isu, tetapi kualitas nyata AI harus universal, yang mengapa saingannya, dari kode sederhana ke Agen nyata, ditujukan masalah dari solid state untuk adaptasi。
Jadi, aliran kerja Dinamis, aliran kerja dinamis bukan "percakapan satu arah yang lebih cerdas," itu hanya..Proses penelitian itu sendiri terstruktur。
Aku harus memulai selusin dialog independen, dan sekarang aku turun ke tiga sampai empat. Meskipun konsumsi Token telah meningkat puluhan kali。
Lalu kenapa tiga atau empat kalisaya rasa penyebab akarnya adalah perbedaan permintaan ini。
Nomor satu:Keparahan mekanisme sertifikasiAKU MELAKUKAN PENELITIAN TERUTAMA PADA TEKNOLOGI BARU DI RANTAI BLOK, DAN BANYAK HAL, DOKUMEN RESMI TERTINGGAL, DENGAN LEBIH BANYAK REFERENSI UNTUK KODE SUMBER TERBUKA, TRANSAKSI RANTAI, DLL, SEMENTARA SAAT INI AI DEFAULT DIDASARKAN PADA DOKUMEN RESMI, BUKAN PADA VERIFIKASI FAKTUAL。
KeduaPemikiran yang mendalamIni, meskipun mungkin untuk berpikir tentang isu yang sama melalui praset aliran kerja (subAgen, yang pradefinisi berbagai dimensi). Tapi AI baik pada model pemikiran arus utama, yang tidak cukup untuk data yang sangat baru, sangat dalam dan kurang。
Nomor tiga:Solusi desain dan validasi rekaanMAKSUD DARI SOLUSI BUKAN UNTUK MENYAJIKANNYA, MELAINKAN UNTUK MEMVALIDASINYA, MENDUKUNGNYA, MENGANDALKAN PENGUKURAN MEKANISME, MASUKAN DAN BIAYA YANG ADA, DAN TENTU SAJA, UNTUK MENGAJARKAN AI LEBIH BAIK, MESKIPUN HAL INI BERTENTANGAN DENGAN INTEROPERABILITAS。
Dan akhirnyaPemkayaan informasi yang ekstremIni adalah tentang kembali ke tingkat pemahaman dari penonton pesan, di mana beberapa orang tidak memiliki latar belakang dan membutuhkan gambar Anda, sementara yang lain membutuhkan kata-kata Anda untuk membuatnya terkesan。
