
如何用 Claude 的 Dynamic Workflows 做深度研究
什么才是AI时代下人该做的深度研究,以及如何构建我与AI的协作互补关系。

这三年下来,我已经离不开用 AI 辅助做行业研究,为此还搭建过一系列的 skill 和辅助系统,解决信息的筛选,归纳,联结,验证,沉淀。
直到这周深度体验了 Claude Code 的动态工作流之后,才发现"人不要和大时代做对抗"这句话的真正含义。
再次思考下:什么才是AI时代下人该做的深度研究,以及如何构建我与AI的协作互补关系。
一、从调研的陷阱说起
做技术调研其实是一件充满陷阱的事(无论对人还是AI),毕竟从调研的开始,会接收到大量的信息,信息观点越来越多,结论越来越模糊。所以时刻要懂得回归目标本身。
这也一直以来,为什么AI不够优秀的地方,因为从注意力和联想的角度看,他会比人类更困于当前的信息量,并且对于真正有价值的跨界联想很薄弱。
当然 AI 够优秀的地方,则是他的执行力,会以agent的形式一层层的去寻找,归纳,总结,完全可以避免细节的损耗。
虽然我这半年都没怎么对外发公众号了,但几乎行业里主流的战场我都有在全面的关注和研究,而支撑这输入输出的,则是一套自己的 deep-research 系统。
而面对上周 Claude Code 上线了 Dynamic Workflows 这个功能,我想互相battle下,看他的默认能力,能否完全超越我自己。
二、Dynamic Workflows 是什么
Dynamic Workflows(动态工作流)它的核心思路是:在执行任务之前,先由 AI 自动设计这个任务应该用什么工作流来完成,然后再启动执行。
这和我们以前用的"计划模式"和“skill”有本质区别。计划模式是把任务拆得更细,但不一定符合某种合理的工作流,随着你提示词的安排,才有可能会加验收指标(这对Research而言至关重要),同理你也只有在有提示词的情况下,他才会更好的预设一些harness规则。
但是动态工作流则会自动把验收逻辑、结果收敛、对抗验证这些东西都组进来。
触发方式很简单,直接在cc里使用/deep-research 然后提供一些调研模板和入口资料即可,如果想单独用动态工作流的能力则是提示词或直接说ultracode,使用前注意,token消耗约为平常的数十倍。
三、内置的六种工作流模式
动态工作流的底层,是官方总结的六种核心调度模式,这是它为什么比普通的对话/agent/skill更强的原因。
其实 这六种模式背后其实只有两个核心问题:任务怎么拆?结果怎么合? 分开六种本质就是对这两者的排列组合。
3.1 路由模式(Classify-And-Act)
先由一个 agent 分辨任务类型,再把任务分发给最适合的专门 agent 去做。核心逻辑是路由的选择逻辑,而非并行或迭代。一个任务只走一条路径,其他路径完全不执行。
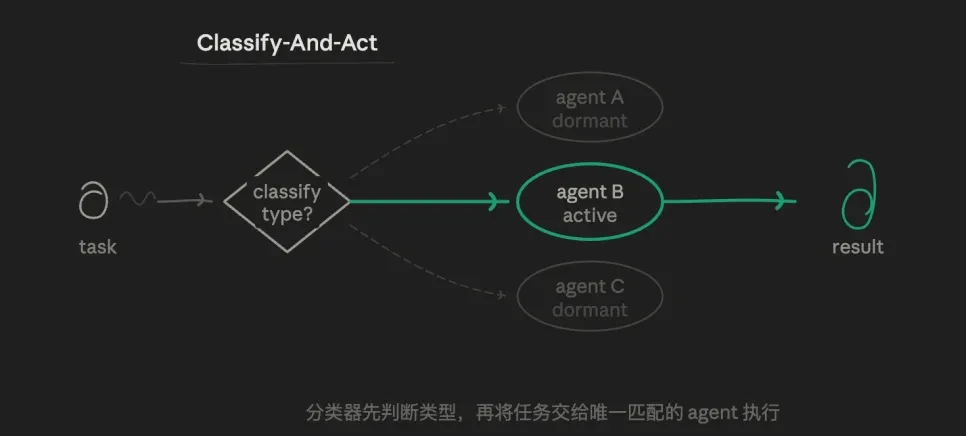
比如我可以先有三个预设subagent角色:一个严格验证数据的分析 agent、一个擅长写作的输出 agent、一个专门找漏洞的挑战 agent。让路由层会判断当前子任务适合交给谁,而不是让一个 agent 全包。
这种模式的价值在于:精准和节俭,每个 agent 的提示词可以高度独立,不被其他目标干扰,形成有垂直深度的探索。token 消耗最低,响应速度最快。职责边界非常清晰。
缺点也很显著,对边界模糊的任务(比如"既是技术问题又是账户问题")处理能力弱。
3.2 拆分合并(Fan-out & Merge)
也是我最常用的模式,核心逻辑是并行+合并。任务拆成 N 个独立子任务同时跑,等所有完成后统一合并。

优势在于速度和隔离。总耗时约等于最慢那个子任务,而非所有子任务之和。每个子任务有独立 context,互不干扰,也不会因为某个子任务的噪声污染其他子任务。
弱点是 token 成本是串行的 N 倍,合并层(Synthesize)本身也有难度——N 路结构不一致的输出怎么融合是个设计挑战。子任务划分不好会导致遗漏或重复覆盖。
3.3 对抗验证(Adversarial Verification)
核心逻辑是检验,对同一个结论,让多个 agent 从"反驳"的角度去挑战,票数过半才算通过。
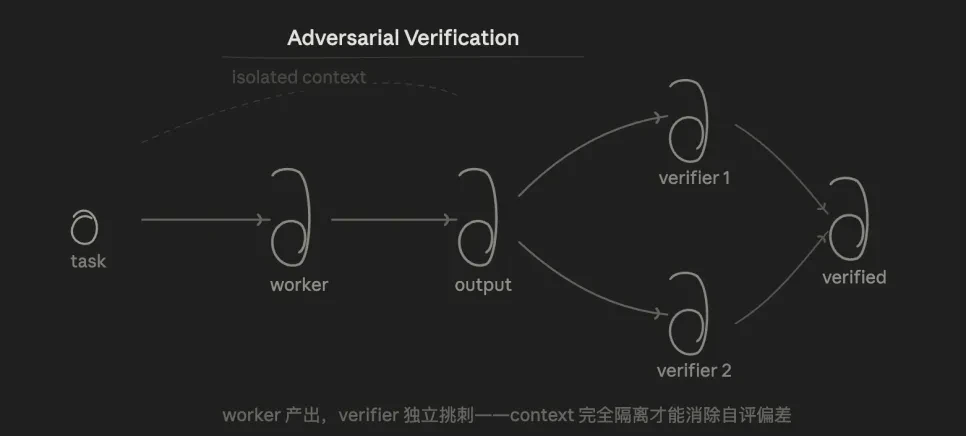
优势在于,由于 Verifier 不知道 Worker 的思路,只看结果,从结构上消除了"让模型检查自己写的代码"时的自评偏差。
这种模式,解决了一个长期困扰我的问题:我们经常用口语化的方式跟 AI 聊,但 AI 倾向于顺着你的预期去回答,容易产生"确认偏误"。通过对抗验证强迫 AI 去寻找反例,去基于数据和实验来验证,而不是迎合你的想法。
但是,验证这件事,他如果给出错误的判断, 则会带偏Worker,去迎合Verifier。所以优选要基于可复现的事实,而非借助观点。
开个玩笑的说,你如果让AI找问题,他能无穷无尽的找出问题,所以你得限制他找问题的边界。
3.4 生成与过滤(Generate & Filter)
核心逻辑是发散再收敛。先刻意产生过量的候选,再用 rubric 淘汰到精华,只保留高置信度的结果输出。

与其让一个 agent 输出一个"还行"的答案,不如让它生成十个,再用验证层筛选。因此优势在于多样性。多个 Generator 可以用不同策略、不同提示词,产出人工难以预想到的解法,过滤步骤让最终输出质量高度集中。
弱点则是,Filter 的 rubric 质量直接决定最终效果,rubric 设计错误等于整个流程报废
适合的场景是事先不知道正确答案的情况、需要从多种可能中择优、对多样性有明确需求。
和 Fanout-And-Synthesize 的只是表面相似:两者都是"多路并行 → 单一输出",最容易混淆。
关键差异在于意图:Fanout 的每一路都处理任务的不同部分,结果是互补的,合并时所有路都有贡献;Generate-And-Filter 的每一路处理的是同一个任务,结果是竞争的,合并时大部分会被丢弃。前者是"拼图",后者是"选美"。
3.5 锦标赛模式(Tournament)
核心逻辑是竞争淘汰。N个agent各自独立做同一件事,通过 pairwise 对比逐轮淘汰,最终选出最优解。

这个我以前手动干过——同一份代码变更跑两三个版本,再让 AI 比对哪个更好。现在可以直接在工作流里编排进来。
优势在于评判稳定性。两两对比("A 和 B 哪个更好?")比绝对评分("给 A 打分")稳定得多,因为排除了评分标准漂移的问题。结果经过多轮竞争,最终胜者的可信度高。
和 Generate-And-Filter 的也是表面相似: 两者都是从多个候选中选优。关键差异在于选优机制:Tournament 用 pairwise judge 两两比较,是"让候选者互相竞争"。当 rubric 难以量化、判断本质上是相对的时候,会更可靠。
3.6 循环模式(Loop)
核心逻辑是自适应迭代,不断尝试,遇到阻力就收集错误信息,补充上下文,重新尝试,直到满足验收条件为止。

本质上是在对抗 AI 的随机性:多试几次,总会撞上更好的结果。但更成熟的做法是结合对抗验证,让每次循环都带着更多信息去执行,而不是纯靠随机。
优势在于对工作量未知的任务的处理能力。其他五种模式都假设任务边界是确定的, Loop Until Done 是唯一能处理"不知道要做多少轮"的模式
弱点是潜在的失控风险——停止条件设计不好会无限循环。每一轮的 agent 是全新的 context,无法积累跨轮状态(除非显式写入文件)。
四、我自己的 skill 和官方工作流的 Battle
在动态工作流出来之前,我专门设计过一套自己的 deep-research 。我那套 skill 的逻辑大概是这样:
- 只给一个简单的信息(比如某项目新上了某功能)
- 让 AI 去搜索所有相关资料:官方文档、源代码、市场舆论
- 把信息压缩成有意义的摘要
- 多个 agent 角色做对抗分析,生成报告
- 自动去重,因为多 agent 的内容重复率很高
用了一段时间,我觉得挺好用的。但它有一个根本性的缺陷:缺乏以目标为导向的收敛。
而且很多时候即使有第五步的去重,但这个时候,他经常删除掉有价值的信息,如果不做去重,又特别容易 skill 会给你一篇万字长文,信息很全,但没有直接告诉你"这件事跟你有什么关系、你应该怎么做"。
然而,研究是为了“决策”服务的,这就是为什么很多skill 只能止步于研究本身,有80分,但少了最关键的20分。
以至于AI在初步完成了研究后,还需继续十次的思考和对话,才能达成满意的周全的结论。
官方动态工作流多做了什么
通过这周几次复杂调研任务的实验,我发现,Claude Code 内置的 deep research 工作流(注意不只是skill,而是编译内嵌到cc里的模块),对比在我自己 skill 的基础上,多了几个关键环节:
- 问题拆解层:它不会直接开始搜索,而是先开始问问问题,把我的问题拆成多个子问题:你真正想搞清楚什么?这件事和你有什么关系?哪些维度值得深究?这一步我以前是跳过的。
- 可信度评估:对每条信息评估可证伪性,类似传统 SEO 里的权威性评分——来源是否可信?引用次数如何?这是我以前没想到要加的环节。
- 交叉删除而非平均合并:我以前的做法是平均选取所有结论,所以文档很大。动态工作流会对每个结论做多 agent 投票,票数不足的删掉,不是简单合并。
- 目标导向的输出:最终的报告不是信息堆砌,而是围绕你的原始目标给出判断和建议方案。而实现这点的关键在于他调度多子agent的预设能力,我之前之所以skill容易缺少最终目标导向,就是因为在海量信息后,指令权重的衰减。
这些机制解决了什么问题?
针对的就是 AI 做长任务的几个典型问题:
目标漂移:任务开始时状态好,到中间就不知道在干什么了,结束时又重新找回节奏——类似人类上课走神。任务越长越明显。
过早停止:跑着跑着遇到困难,AI 认为自己"完成了"就停下了,实际上验收标准根本没过。
上下文污染:单个 agent 做复杂任务,前置的大量 prompt 会压缩后续执行空间。更好的方式是把前置 prompt 控制在几 k 以内,用多 agent 来分摊上下文。
输出偏向:AI 倾向于顺着你的预期回答,口语化提问更容易触发这个问题。
而动态工作流用结构化的方式解决了这四个问题:自动加验收指标防止过早停止;并行隔离上下文;对抗验证抵消输出偏向;拆解问题层层约束 AI 先理解目标再行动。
五、小结
最后,笔者作为个常年的研究工作者,对此CC新机制叹为观止,它内置的六种模式——路由选择、拆分合并、对抗验证、生成过滤、锦标竞选、Loop循环——覆盖了绝大多数复杂研究任务的调度需求。
让我不再需要手动设计 agent 调度,也不再需要自己做去重和交叉验证,这些都被编进工作流本身了。
而且他特别适合在缺少信息,开发性问题的探究上做思考,因为天然的多agent调度+任务目标的拆分,让他在通用性上再次提升,其实早在3年前的AI,对于一个层层约束,只让他解决极为清晰的小问题上,已经做得很好了, 但是AI真正的质变还是在于通用性,这点才他的竞争对手,从简单的代码变为真正成为Agent,从固态解决一个问题,到适应任何问题。
所以 Dynamic Workflows 动态工作流不是"更聪明的单次对话",而是把研究流程本身结构化。
原本我需要发起十几次独立对话的调研,现在压缩到 3-4次。 虽然对应的Token消耗是数十倍的增长了。
那为什么还需3-4次呢? 我觉得根因在于这些需求的差异。
第一是验证机制的严苛度,我是主要对区块链上的新技术做研究,很多事情,官方文档都是滞后的,有更值得参考的开源代码,链上交易等等数据,而目前AI默认还是以官方文档为准,而不是以事实性验证为准。
第二是完全跨界的深度思考,这点虽然通过工作流预设可以解决一些(预定义各种维度的subAgent)来对同一个问题进行思考。但是AI擅长的还是主流思考模型,对非常新的,非常深刻,缺少数据依据的,则稍显不足。
第三是解决方案设计与验证, 解决方案的意义不在于提出而在于验证,支持,他依托于对现有机制,投入和成本的衡量,如果很好的调教AI当然可以做得更好,不过这就与通用性有所违背了。
最后是极致的信息浓缩,这则是需要回归到对信息的受众的了解程度上,有的人毫无背景基础,需要你拟人的形象的表述,而有的听众,需要你一句话打动他~。
