
Claudeの動的ワークフローに関する詳細な研究を行う方法
人工知能の年齢層の人々が行うべき研究の深さと、私とAIの間の補完的な関係を構築する方法は何ですか。

過去3年間、AIサポートで業界調査をしてきましたが、情報、要約、接続、検証、堆積のフィルタリングを整理するための一連のスキルと支援システムを構築しました。
週が「人は大きな時間と戦うことはありません」というフレーズの本当の意味であるクロードコードの動的ワークフローを通過するまではなかった。
再び考える: 人工知能の年齢層の人々が行うべき研究の深さと私とAIの間の補完的な関係を構築する方法は何ですか。
I. 研究の罠から始まる
技術的な研究は、実際には、トラップ(人とAIのために)であり、結局のところ、膨大な情報が研究の始まりから受け継がれており、多くの観点とますます漠然とした結論が増えています。 それでは、それ自体を戻すという目標を理解する時間です。
そこで、AIの注目と協会の観点から、AIが十分でないのは、現在の情報量と、真に価値あるクロスボーダー接続の弱点において、人間よりも一層引き渡されます。
もちろん、AIは見つけ、要約、そして単に細部の損失を避けることのタスクを遂行することができるように十分によいです。
過去6ヶ月であまりの広報性を与えられていないが、業界にほとんどすべての主要分野を探し、研究してきましたが、この入力は自分のディープリサーチシステムでサポートされています。
そして、先週のクロードコードの線、ダイナミックワークフローの面で、お互いにダウンして、デフォルトのパワーが私を超えているかを見てみたいです。
動的ワークフローとは
動的ワークフローのコアラインは次のとおりですミッションが実行される前に、AIはタスクにワークフローが使用されるかを自動的に設計し、実行を開始します。
基本的には「プランモデル」と「スキル」とは違います。 計画モデルはタスクを破棄することですが、必ずしも合理的なワークフローに対応していません。 あなたのヒントで受諾インジケータ(研究のために不可欠である)を追加することが可能であり、あなたはあなたが持っている場合は、いくつかのハーネスルールを設定するために準備が良いでしょう。
しかし、動的ワークフローは、受諾ロジック、結果の制限、およびこれらのことを検証するための対立を自動的に組み込む。
トリガーは cc/deep-research で直接単純です その後、いくつかの研究テンプレートとアクセス情報を提供するのに十分でしょう。また、動的ワークフローを単独で使う能力がヒントまたは直接のultracodeで、使用前に、トークンは数十倍の時間を消費します。
3。 6つのワークフローモードをインライン化
動的なワークフローの一番下は、6つのコアの動きパターンが正式にまとめられています。そのため、通常の対話/エージェント/スキルよりも強くなります。
実際には、6つのモデルの背後にある2つのコアの問題しかありません:タスクが壊れる方法は? それはどのようにフィットしますか。
3.1 & nbsp; ルートモード (Classify-And-Act)
タスクは、最初にエージェントによって識別され、最も適切な専門 に配布されます;エージェント お問い合わせ コアロジックは:ルート選択の論理、平行か反復的。 1つのミッションは1つのパスだけをフォローし、他のパスは完全に非導入です。
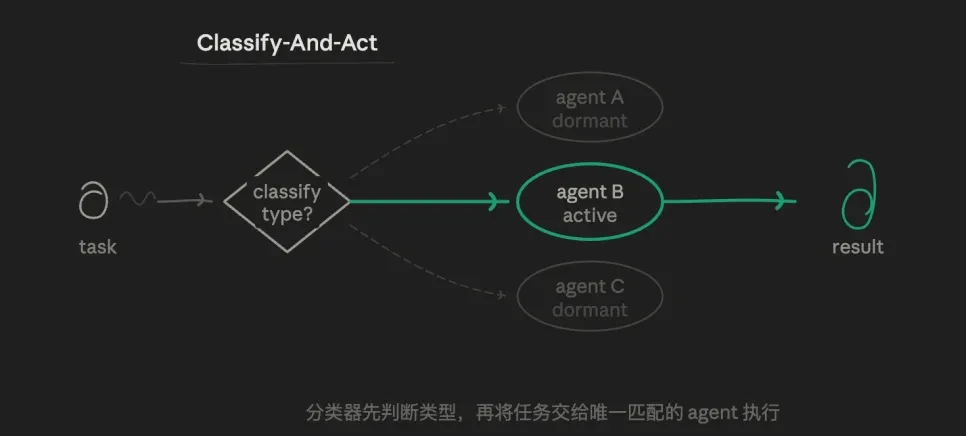
例えば、三つのプリセットのサブエージェントのロールから始めることができます: 厳格なデータ解析の意図の分析、意図した記述で良い出力、ループホールを見つけることに専念するチャレンジ。 ルータは、現在のサブタスクが誰であるかを、個々のパックを割り当てる代わりに判断します。
このモデルの値は、正確で経済的であり、各エージェントのヒントは、他のターゲットから高度に独立して自由であり、垂直方向の深さ探査につながることです。 トークンは最低消費量、最速応答を持っています。 責任のラインは非常に明確です。
また、境界線をぼかすタスクに対処するための重要な欠点と弱い能力(「技術的およびアカウントの問題」など)もあります。
3.2 スプリットアマルゲーション(ファンアウト&マージ)
最も一般的なモデルで、コアロジックは並列で統合します。 タスクは N の別々のサブタスクに分割され、同時に実行し、すべてを完了したらそれらを統合します。

利点は速度および分離です。 合計時間は、最も遅い投稿の合計ではありません。 各投稿は、干渉することなく独立した被写体であり、他の投稿を1つの投稿のノイズのために汚染しません。
ウェイクネスは、トークンのコストが3倍のシリアル数であり、統合レイヤー自体は困難であるということです - 矛盾するNロード構造と出力を統合する方法は、設計課題です。 サブタスクのポア部は、オミッションやカバレッジの重複につながる。
3.3 カウンター検証(広告検証)
コアロジックは:テスト、同じ結論のための多数の及びnbsp;エージェント "refuting" の観点から、投票の半分以上です。
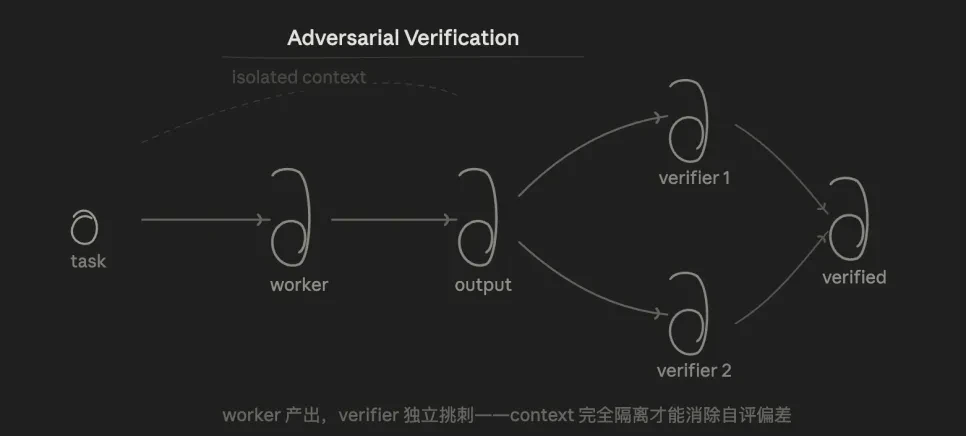
利点は、VerifierがWalkerの考え方が何であるかわからないので、それはちょうど結果を見て、構造的に自己評価バイアスを「書いたモデルをチェックしてみましょう」で排除するということです。
このパターンは、長年に渡る問題を解決します。私たちは、多くの場合、オーラルな方法でAIに話しますが、AIは期待に応える傾向があり、それは「偏差を認識する」のが簡単です。 検証を進めることにより、AIがリバース例を探し、データと実験に基づいてテストします。
しかし、これを検証するために、彼は間違った判断を与えた場合、彼は彼を検証者に連れて行きます。 そのため、好みの選択肢は、視点ではなく、反復可能な事実に基づいています。
私はAIが問題を見つけた場合、彼はそれをすべての時間を行うことができますので、あなたは彼が問題を見つける境界を制限する必要がありますと言うのに冗談です。
3.4 生成とフィルタリング (生成 & フィルター)
コアロジックは:広がるつもりですお問い合わせ まず、候補者の過度な数を意図的に作成し、それを rubric で段階的にし、出力の高い自信を保ちます。

エージェントが「ファイン」の答えを出力するのではなく、10を生成するのが良いので、認証レイヤーでフィルタリングします。 その利点は多様性にあります。 複数のジェネレータは、さまざまな戦略、異なるヒント、人工的に予測しにくい出力ソリューション、およびフィルタリング手順を使用して、最終的な出力品質の高い濃度を可能にします。
弱点は、フィルタの rubric 塊が直接エンド効果を決定し、 rubric 設計エラーは、プロセス全体の終わりであるということです
適切なシナリオは、正しい答えが事前に知られていない状況であり、利点はさまざまな可能性から描画する必要がある状況であり、多様性のための明確な必要性がある。
Fanout-And-Syntheseize は単なる表面に似ています「並列で複数の道路、単一の出力」は、混乱する最も簡単です。
重要な違いは..こだわり(a) ファンアウトのすべての道路は、ミッションの異なる部分と取引します, 結果は補完的であり、すべてのパスは合併に貢献します; ファンアウトのすべての道路は、同じタスクで取引します, 結果は競争であり、合併のほとんどは廃棄されます. 第1はパズルで、第2弾は美のページです。
3.5トーナメント
コアロジックは競争フェーズアウトです。 Nのエージェントは、採用とnbspで、同じことを行います。 対面 対面フェーズアウトを比較することにより、最終的に最良のソリューションを選択します。

手動で行ったのは、同じコードが2つまたは3つのバージョンを変更し、AIが正しいものよりも優れている。 ワークフロー内で直接整理できるようになりました。
利点は安定性を判断することです。 2つのコントラスト( "A" と "B" がより良いですか?)は、評価基準のドリフトを除外するので、絶対的な評価( "A" の評価)よりもはるかに安定しています。 結果は競争の複数のラウンドであり、最終的な勝者は高い信頼性を持っています。
Generate-And-Filter と同様です: 両者は複数の候補から選択されます。 主要な違いは、選択メカニズムです。トーナメントは、2と2の比較で、「候補者を支持する」です。 rubricが量子化し、判断が自然に相対的に困難な場合、より信頼性があります。
3.6 ループ
コアロジックは:適応から— 受信条件が満たされるまで、虚偽の情報を収集し、コンテキストを補完する継続的な試み。

AIのランダム性に対する本質的に:より多くのことを試みて下さい、よりよい結果に常にバンプして下さい。 しかし、対面認証を結合し、各サイクルが単にランダムではなく、より多くの情報で実装できるようにするために、より成熟するでしょう。
この利点は、未知のワークロードでタスクを処理する能力にあります。 他の5つのモデルは、ミッション境界が固定されていると仮定します, Done までのループ; 「何ラウンド知られていない」を扱うことができる唯一の1
弱点は、制御の損失の潜在的なリスクです。 - 条件を停止することは、無期限に循環するように設計されていません。 アンエントの各ラウンドは、クロスホイールの状態を蓄積できないまったく新しいコンテキストです(ファイルが明確に書かれていない限り)。
IV. 私のオーウェン・スクヒルと公式バトル
動的な仕事が出て来る前に私自身のセットを設計しました。 deep-research 私のスキルロジックはおそらくこれです:
- 1つの簡単なメッセージのみ(プロジェクト上の新機能など)
- AIが関連するすべての情報を検索してみましょう: 公式ファイル、ソースコード、市場の意見
- 情報を意味のある要約に圧縮する
- 複数のエージェントがレポートを分析し、生成する役割
- 複数のエージェントコンテンツの繰り返し率が高いため、自動的に重大
しばらく経ってみると、とても便利です。しかし、それは基本的な欠陥を持っています:目標指向の成長の欠如。
そして、数回、第5ステップのヘビー級が存在しても、この時点で、彼はしばしば貴重な情報を削除し、それが十分に重くない場合、それはあなたに長く、完全なテキストを与えるためのスキルのために特に簡単ですが、あなたに言うべきではありません、「これはあなたと一緒に行う必要がありますか。
しかし、「意思決定」のために、これは、研究自体で多くのスキルが止まる理由です。80ポイント、最も重要な20ポイント未満。
そのためには、研究の初期完了後、AIは10の反射と対話を続け、満足と徹底的な結論に達する必要があります。
正式な動的な作業は
今週の複雑な研究ミッションでいくつかの実験を通して、Claude Code の組み込みとnbsp があることがわかりました。Deep Research & nbsp; Workstreams(単なるスキルではなく、CC で埋め込まれたモジュールをコンパイル)は、自分のスキルにいくつかの重要なリンクを持っています
- 問題の解体: 検索を開始するだけでなく、質問をしたり、質問をサブ質問にしたり、質問をしたり始めます。本当に知りたいですか? どうすればいいですか? どのような寸法を調べる価値がありますか? 前にこれを実行しました。
- 信頼性評価• 伝統的なSEOで発見されたものと同様の知覚的評価であるパージュリーのための情報の一部を評価する - ソースは信頼できる? 基準はいくつですか? そういうわけで、追加するつもりはない。
- 平均マージの代わりにクロス削除: 私は平均してすべての結論を選ぶために使用しました、従ってファイルは大きいです。 動的ワークフローは、各結論に投票を投げ、不十分な投票が削除され、単にマージされない。
- ターゲット指向の出力: 最終報告書は、情報の積み重ねではなく、判断と本来の目的に関する提案ではありません。 これへの鍵は、複数の子供を移動させる彼の事前設定の能力であり、私が以前に熟練した理由は、私はエンド指向のオリエンテーションを持たないので、私は私が探しているものを確信していませんコマンド重量の決定お問い合わせ。
これらのメカニズムが解決するものは何ですか
長いミッションをやってAIに関する一般的な質問のカップルです
ターゲット漂流ミッションは良い形で始まり、途中で何をすべきかを知り、新しいリズムで終わるのではなく、人間のためのレッスンです。 ミッションが長いほど、より明白です。
早めに止まります: 硬い走り、AIがやっていると思い、止まり、実際は受け入れない。
コンテキスト汚染: 個々のエージェントは複雑なタスクを実行し、多数のプレポジションは、その後の実行スペースを圧縮します。 いくつかの k 内でプレプロンプトを維持し、複数のパーティの間でコンテキストを広げるより良い方法。
出力バイアスAIは期待に沿う傾向があり、それをトリガーする経口質問をするのは簡単です。
動的ワークフローは、これらの4つの課題を構造化した方法で解決します。自動受容体インジケーターは、早期の停止を防ぐことができます。 並列分離 コンテキスト; 対比出力偏差を相殺し、制約の層を解体すると、AIはアクションの前にターゲットを理解します。
インフォメーション
最後に、恒久的な研究者として、CCCの新しいメカニズムは、6つのモデルがそれに埋め込まれているという事実に感銘を受けています - ルートの選択、分割、抗認証、フィルタリング、チャンピオンシップキャンペーン、ループ循環 - ほとんどの複雑な研究ミッションの動き要件をカバーしています。
なので、手動で、エージェントの動きを設計する必要はありません。ワークフロー自体にプログラムされているすべてのものを重み、自分でクロスチェックする必要はありません。
そして、彼は特によく情報不足と開発の問題の探査について考えるために配置されています, 天然の試薬の動きとミッションの目的の分裂は、相互運用性の面で再び彼を提起しました, 3 年前, AIは、非常に明確かつ小さな問題に対処するためにうまく行っていた, しかし、AIの実際の品質は普遍的なものでなければなりませんでした, 単純コードから実際のエージェントへ, 固体状態から適応に問題に対処しました。
つまり、ダイナミックなワークフローは、ダイナミックなワークフローは「スマートな片道の会話」ではなく..研究プロセス自体が構造化されています。
何十もの独立した対話を始める必要があり、今は3〜4人までです。 トークン消費の対応は数十回増加しています。
それから3〜4回以上ですか 私は根本原因は、要求のこれらの違いだと思う。
ナンバーワン:認証メカニズムの重大性ブロックチェーンの新技術を中心に研究をしていますが、多くのこと、公式の文書は後ろに悩まされ、オープンソースコード、チェーン取引などを参照しています。現在AIのデフォルトは公式文書に基づいており、実際の検証ではありません。
第2、フルクロスボーダーディープ思考これは、ワークフロープリセット(サブエージェント、様々な寸法をあらかじめ定義)で同じ問題について考えることは可能です。 しかし、AIは主流の思考モデルで良いです。それは非常に新しく、非常に深く、データがないため十分ではありません。
番号3:ソリューションの設計と検証解決策の意味は、それを提示するものではありませんが、それを検証するために、それをサポートするために、既存のメカニズムの測定、入力とコスト、そして、もちろん、AIをよりよく教えるために、これは相互運用性に反するものです。
そしてついに、極端な情報強化これは、メッセージの聴衆の理解のレベルに戻って行くことです, 一部の人々はバックグラウンドを持っていないし、あなたのイメージを必要としています, 他の人は、彼を印象づけるためにあなたの言葉を必要としながら、。
